
You don’t automate right away…
Process automation using Artificial Intelligence is a complex endeavor. To successfully automate a process, automation systems and their implementers need to effectively incorporate complex technologies, a deep understanding of the business processes, risk-based decision making, and organizational change management all at once! This challenge can feel insurmountable to many organizations looking to start adopting AI-driven process automation. And unfortunately for some, it has proven to be so.
Luckily, there are battle-tested methods for bringing an automation system to life and avoiding the potential pitfalls. Here at Nuclearn, we have developed a project implementation process we call DARSA that helps guide us through automation projects. DARSA helps us deliver maximum value with minimal risk by leveraging an iterative, agile approach to AI-driven automation.
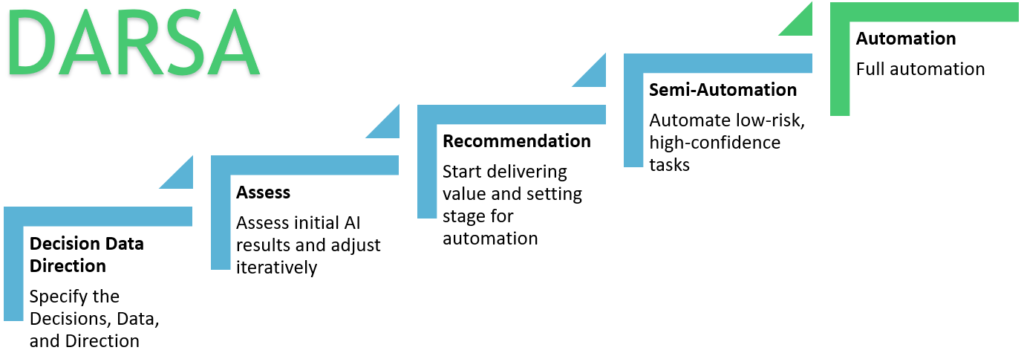
So what is DARSA? DARSA is a five-step linear process that stands for Decisions-Data-Direction, Assess, Recommend, Semi-Automate, and Automate. Each step in DARSA is a distinct phase with distinct characteristics, and transitions between these phases are planned explicitly and usually require system changes. To learn more about DARSA, we must dive into the first phase: “Decisions, Data and Direction”.
1) Decisions – Data – Direction
Before starting AI-driven automation, it is important to specify several key factors that will guide the project. These items are Decisions, Data, and Direction.
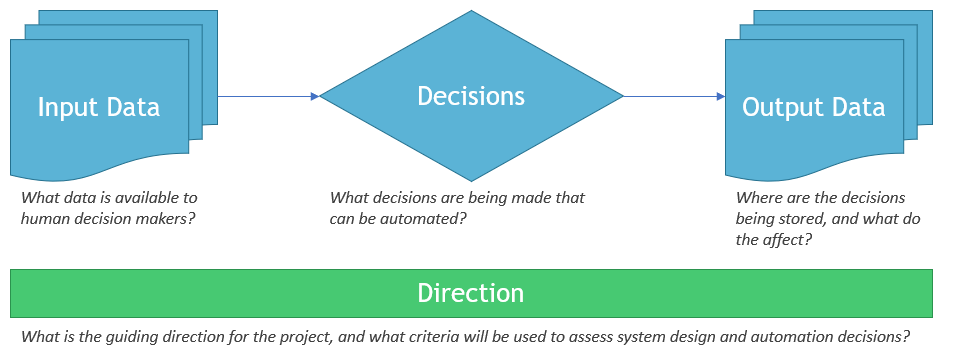
Decisions are the first, and most critical item to define early in an AI-driven automation project. At the end of the day, if you are embarking on an AI-driven automation project, you are doing so because you need to automate challenging decisions that currently require a human. If there is no decision to be made, then AI will not help automation in any meaningful way. If the decisions are trivial or based on simple rules, there is no need for AI. These processes should be automated by traditional software. So the first, essential part of an AI-driven automation project is identifying and defining the decisions that are planned to be automated.
Data is the next item that must be specified. An AI-driven automation project needs to identify two key sets of data: the input data being used to influence decisions, and the data created as a result of those decisions. These are critical, as AI-driven automation relies heavily on machine learning. To learn how to make decisions automatically, machine learning requires historical data. For each decision, there should be a detailed log of all data used at decision time, and a log of all historical human decisions.
Direction. AI projects must begin with clear direction, but unlike large traditional software projects, AI-driven automation projects cannot begin with a detailed project plan laying out detailed requirements gathering and design. AI and machine learning are notoriously unpredictable – even the most experienced practitioners have challenges predicting how well models will perform on new datasets and new challenges. Automation systems often have to evolve around the unpredictable strengths and weaknesses of the AI. As a result, it is important to specify a clear direction for the project. All members of the project should be aligned with this direction, and use it to guide their iterations and decisions. For example, in an AI-driven automation system for helping generate Pre-Job Brief forms, the direction for the project might be “Reduce the amount of time required to assemble Pre-Job Briefs while maintaining or improving the quality of Pre-Job Briefs”. This simple statement of direction goes a long way towards bounding the project scope, ruling out system design decisions that are unacceptable, and fostering potential innovation.
2) Assess
Once the Decisions, Data and Direction are specified, the most important factors for success in an AI-Driven automation project are fast iterations and good feedback. That is why the second phase in DARSA is “Assess”. During this stage of the project, nothing is actually automated! The “automation” results are being shared with subject matter experts, so they can assess the results and provide feedback. Automation system designers and Data Scientists are already quite familiar with testing how well their system works via various traditional methods. While these can help with generating accuracy metrics (the model is 95% accurate!), these methods are quite poor at evaluating exactly where the automations will fail or be inaccurate, why they are that way, and what the impacts are. The Assess phase is often where important risks and caveats are identified, and where additional considerations for the project are discovered.
Let’s take for example my experience with a project attempting to automate the screening of Condition Reports (CR) at a Nuclear Power Plant. One of the key decisions in screening a CR is determining whether the documented issue has the potential to affect the safe operation of the plant, often referred to as a “Condition Adverse to Quality”. Before even showing our AI model to users, my team had produced some highly accurate models, north of 95% accurate! We knew at the time that the human benchmark for screening was 98%, and we figured we were very close to that number, surely close enough to have successful automation. It was only after going through the “Assess” phase that we learned from our subject matter experts that we had missed a key part of the automation.
We learned during the Assess phase that not all Condition Reports are the same. In fact, there was a drastically asynchronous cost associated with wrong predictions. Overall accuracy was important, but what would make or break the project was the percentage of “Conditions Adverse to Quality” that we incorrectly classified as Not Conditions Adverse to Quality. The reverse error (classifying Not Adverse to Quality as Adverse to Quality) had a cost associated with it – we might end up performing some unnecessary paperwork. But get a few high-profile errors the other way, and we would potentially miss safety-impacting conditions, undermining regulatory trust in the automation system and the CAP Program as a whole.
As a result, we made some fundamental changes to the AI models, as well as the automation system that would eventually be implemented. The AI models were trained to be more conscious of higher-profile errors, and the automation system would take into consideration “confidence” levels of predictions, with a more conservative bias. A thorough Assessment phase reduced the risk of adverse consequences and ensured any pitfalls were detected and mitigated prior to implementation.
3) Recommend
After the Assess phase, Recommendation begins. The Recommend phase typically involves providing the AI results to the manual task performers in real-time, but not automating any of their decisions. This stage is often very low risk – if the AI system is wrong or incorrect there is someone manually reviewing and correcting the errors, preventing any major inaccuracies. This is also the first stage that realizes delivered value of an AI-driven automation system.
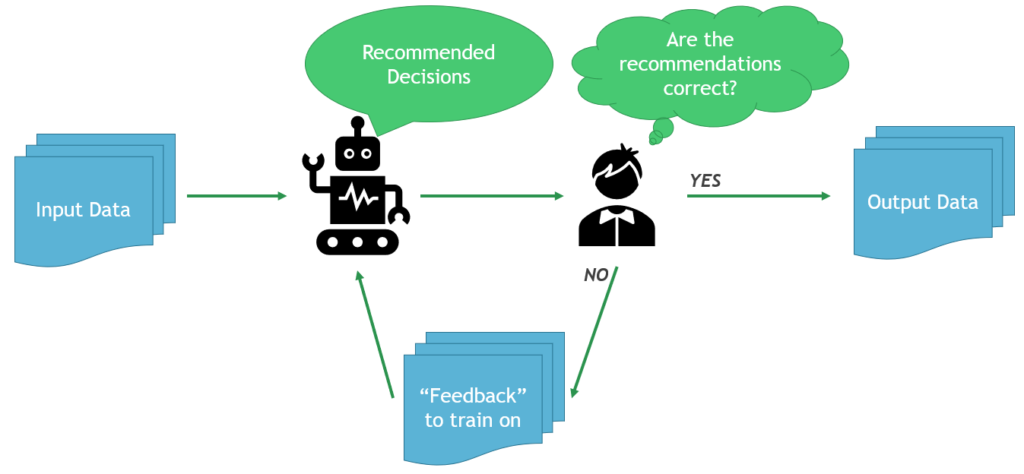
Increased manual efficiency is often recognized as a benefit in the Recommend phase. In the majority of cases, it is physically faster for someone to perform a review of the AI’s output and make small corrections versus working the decision task from start to finish. Paired with a proper Human/AI interface, the cognitive load, manual data entry, and the number of keystrokes/mouse clicks are drastically reduced. This helps drive human efficiencies that translate to cost savings.
The Recommendation phase also permits the capture of metrics tracking how well the automation system is performing under real-world use. This is absolutely critical if partial or complete automation is desired. By running in a recommendation setup, exact data about performance can be gathered and analyzed to help improve system performance and gain a deeper objective understanding of your automation risk. This is important for deciding how to proceed with any partial automation while providing evidence to help convince those skeptical of automation.
This stage may last as short as a few weeks, or as long as several years. If the automation system needs additional training data and tweaking, the recommendation phase provides a long runway for doing so in a safe manner. Since the system is already delivering value, there is relieved pressure to reach additional levels of automation. On some projects, this phase may provide enough ROI on its own that stakeholders no longer feel the need to take on additional risk with partial or complete automation.
4) Semi-Automate
The next step in DARSA is “Semi-Automate”. This is the first stage to both fully realize the benefits and risks of automation. This phase is characterized by true automation of a task – but only for a subset of the total tasks performed.
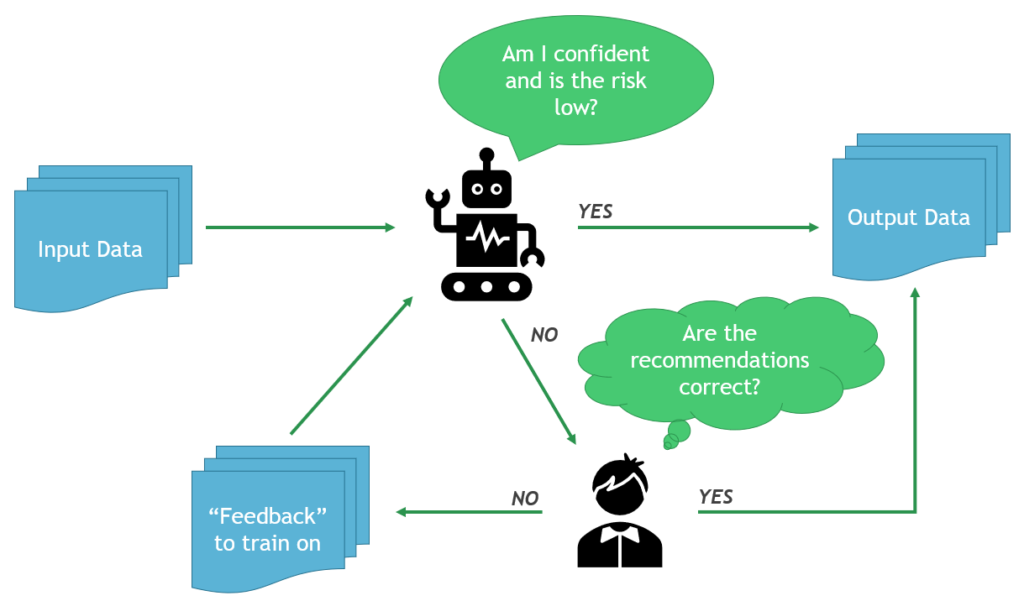
The metrics gathered in the Recommend phase play a key role here, as they can inform which parts of the task are acceptable for automation. As the system encounters different inputs and situations, total system confidence will vary. Based on this confidence, among other metrics, automation can be implemented as a graded approach. Low-risk, high-confidence tasks are usually automated first, and after the system continues to learn, and stakeholder confidence is improved, higher-risk automations can be turned on.
For example, take a system intended to automate the planning and scheduling functions required for Nuclear Work Management. Such a system would begin to partially automate the scheduling of work activities that have low safety and operational impacts, and the planning of repetitive activities that have little historical deviation in the execution work steps. These activities are low-risk (if something goes wrong there are minimal consequences) and high-confidence (the AI has lots of previous examples with defined conditions).
During semi-automation, it is prudent to still have a manual review of a portion of automated tasks to monitor model performance, as well as provide additional training data. Without manual review, there is no longer a “ground truth” for items that have been automated. This makes it challenging to know whether the system is working well! Additionally, AI performance may begin to stagnate without the inclusion of new training examples, similar to how human performance may stagnate without new learnings and experiences.
5) Automate
The final phase that every automation system aims to achieve: complete automation. This phase is characterized by the complete automation of all tasks planned in the scope of the project. The system has been running for long enough and has gathered enough data to prove that there is no human involvement necessary. From this point forward, the only costs associated with the task are the costs associated with running and maintaining the system. Complete automation is more common with tasks that have a lower overall level of risk, yet require a lot of manual effort without automation. The most common example of this in the Nuclear Industry today is automated Corrective Action Program trend coding.
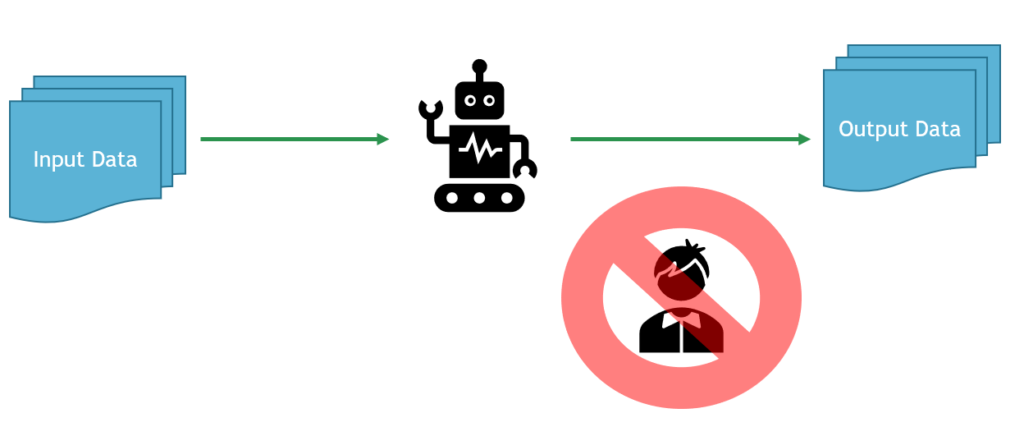
It is expected to jump back and forth between partial and complete automation at some frequency. A common case where this can occur is when the automated task or decision is changed, and the automation system hasn’t learned what those changes are. There will need to be some amount of manual intervention until the system learns the new changes, and full automation can be turned back on. An example of this would be in a “trend-coding” automation system when the “codes” or “tags” applied to data are altered.
Start Using DARSA
DARSA provides a proven roadmap to designing, building, implementing, and iterating an AI-driven automation system. Using this process, organizations embarking on the development of new automation systems can deliver maximum value with minimal risk, using a methodology appropriate for modern AI in practical automation applications.
Visit https://nuclearn.ai to learn more about how Nuclearn uses DARSA to help Nuclear Power Plants achieve AI-driven automation.