
It’s been a while since we last posted about a release, so this update is going to cover two minor releases of Nuclearn! Nuclearn Platform v1.5 and v1.6 have been delivering value to our customers over the last 6 months, and we are excited to share some of the new features to the general public. While extensive detailed release notes can be found at the bottom of this post, we want to highlight three enhancements that delivered considerable functionality and greatly enhanced the customer experience.
- End to End Assessment Readiness
- Prediction Overrides
- Enhancements to Automation and Audit
End to End Assessment Readiness
Nuclearn v1.6 gives customers the ability to automate the entire data analysis portion of preparing for an upcoming INPO, WANO or other audit assessment. Customers can now automatically tag each piece of Corrective Action Program data with Performance Objectives & Criteria, perform comprehensive visual analytics highlighting areas for improvement, and generate a comprehensive Assessment Readiness report including supporting data.
We’ve made significant enhancements to our Cluster Analytics Visualizations, including additional options for customization, improved readability, and additional functionality for search, filtering, and interactivity. Once a potential area of concern is discovered, customers can now save the set of selected labels and analytics parameters in a Bucket.
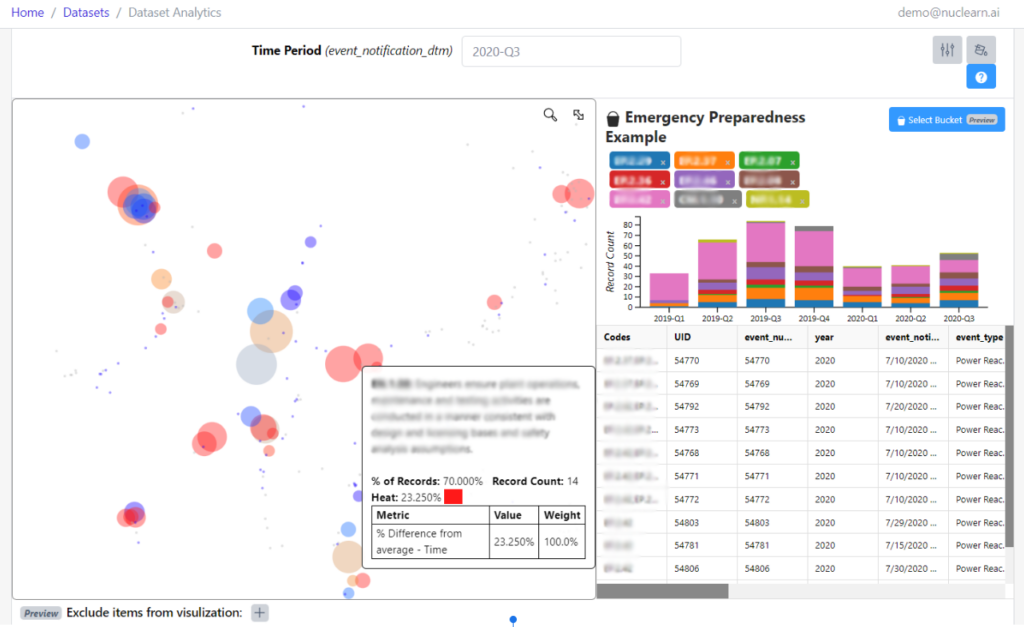
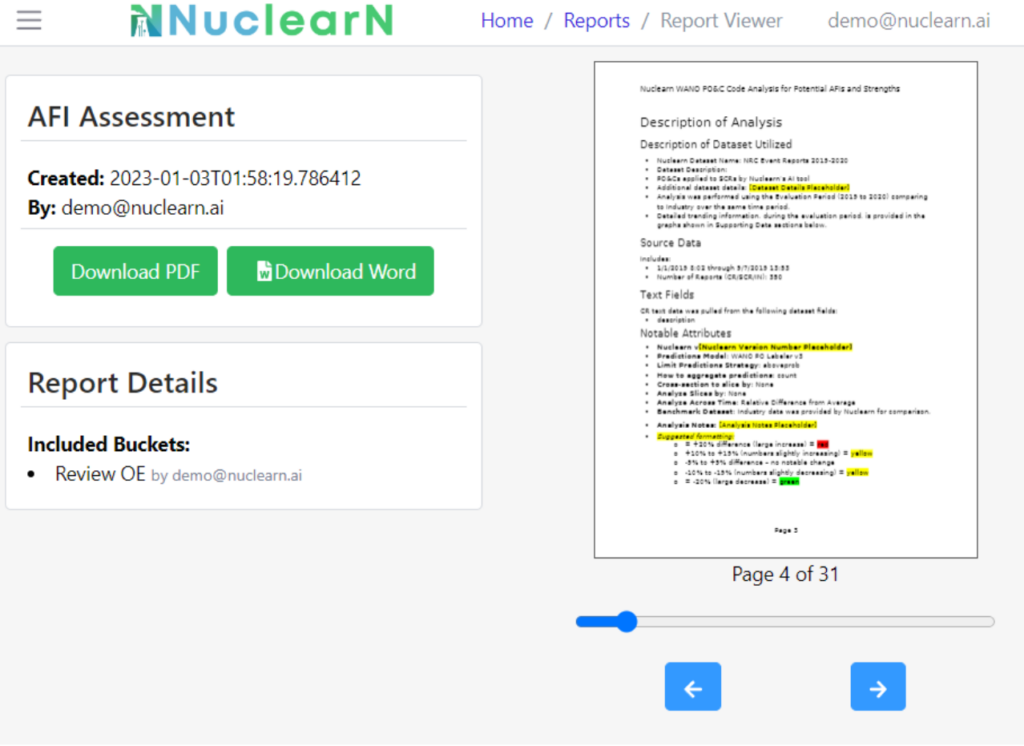
New Report functionality allows customers to generate their own reports within Nuclearn. With v1.6, customers can use the “Automated AFI Report Template” to select multiple Buckets from an Assessment Readiness analysis and automatically generate a comprehensive Assessment Readiness report. These reports are customizable, easily previewed in a browser and can even be downloaded as an editable Word document or pdf file.
Prediction Overrides
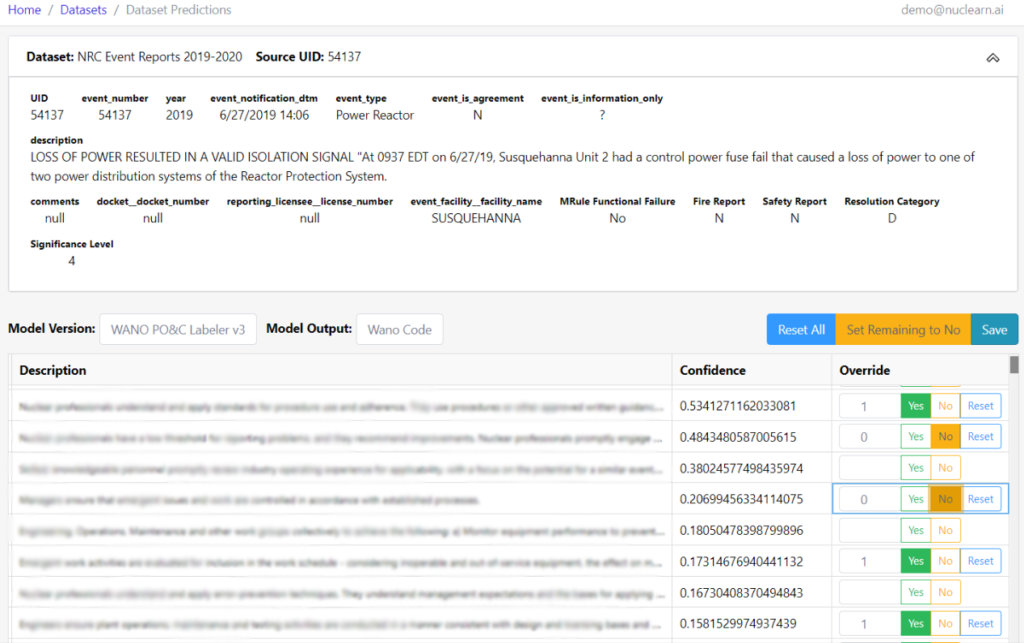
v1.6 now allows our customers to override model predictions. Even the best machine learning models are sometimes wrong, and now users have the ability to view and override model predictions for any record. The overridden values can then be used for subsequent analysis and to improve and further fine-tune future models.
Enhancements to Automation and Audit
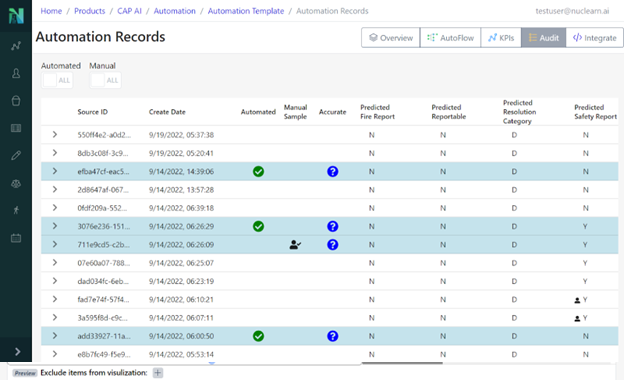
We’ve made various improvements to the Automation functionality within Nuclearn in v1.6, including a major UI update to the Audit pane. It is now much easier to see what records were automated or manually sampled, view incorrect predictions, and explore automation performance. We have also added the ability to “AutoFlow” a Dataset through an Automation Pipeline, allowing customers with non-integrated Nuclearn deployments to easily produce automation recommendations on uploaded CAP data.
Beyond the most notable items we’ve highlighted, there are plenty more enhancements and bug fixes. Additional details can be found in the release notes below, covering all minor and patch releases from v1.5.0 to v1.6.1.
Nuclearn Platform Release Detailed Notes
v1.6.1
- Fixed issue with upgrade script, where RHEL upgrades from 1.5.x to 1.6 would partially fail.
- Updated np_app_storage_service to version 0.4.0 to ensure default report template actually ships with platform.
Upgraded MRE to v0.5.1
- Added artifact record for AFI Report template.
- Updated libreoffice dependencies.
Upgraded frontend to v0.4.1
- Fixed bug in where filters on analytics, where where filter would update incorrectly.
v1.6.0
- Reports functionality now in preview. Automatically generate editable reports from a selection of Buckets.
- Major quality of life enhancements to Analytics and Cluster Analytics, reducing workarounds and improving user experience.
- Improvements to Automations, including a major UI update to the Audit pane.
- Other misc updates.
Updated frontend to v0.4.0
- Reports functionality now in preview.
- Added reports link to sidebar.
- Added ability to generate reports based on a selection of Buckets.
- New report template available to generate an AFIs and Strengths report.
- Easily preview the report in the browser.
- Choose to download the report as an editable .docx or as a .pdf file.
- Significant enhancements to Analytics and the Cluster Analytics visualization.
- Cluster Analytics visualization enhancements
- Added ability to adjust thresholds and colors.
- Improved tool tips to add additional information and make them easier to read.
- Tooltips now additionally include record count and the detailed “heat” calculation.
- Tooltips also added to PO&C badges in the Bucket Details pane.
- Added ability to exclude buckets and PO&Cs from the Cluster Analytics visualization. Exclusion pane is now available underneath the chart.
- Added ability to search the PO&C labels and descriptions using the magnifying glass icon on the top right of the visualization.
- Added ability to reset the zoom/pan on the Cluster Analytics visualization using the expand icon on the top right of the visualization.
- Added support to include more than one split date in an analytic.
- Added ability to include custom filters in an analytic.
- Renamed additional analytics dropdown to “Export”, and renamed options to better reflect what they do.
- Included option in Raw Predictions CSV export to choose whether user wants no additional data or all of the input columns for the analytic in the export.
- Cluster Analytics visualization enhancements
- Major UI update in the Automation Audit pane.
- It is now much easier to see what records were automated or manually sampled.
- Incorrect predictions are now colored red.
- If a record is not automated, the fields that were the cause have a “person” icon next to them, indicating the system was not confident enough in the prediction and a human needs to review the record.
- When an audit record is expanded in the Automation Audit pane, the predictions now appear at the top of the expansion, as well as the actual values (if available). If there is a mismatch, the prediction is colored red.
- “Quality of Life” updates to Automations.
- Added the ability to manually “AutoFlow” a Dataset through an Automation pipeline. This functionality is available on the “Overview” pane of an Automation.
- Automation Configs now have an option to “Prohibit Duplicate Automation”. When this option is enabled, if the Automation encounters a record UID it has processed before, it returns an HTTP 422 error response.
- When creating a new Automation Config, user must select which Model Version they want to use (used to always use the latest model version).
- Misc updates.
- Upgraded react version to 18.2.
- Cleaned up unused code in several source files.
Updated MRE to v0.5.0
- Report generation (preview).
- Create, update and delete reports and report templates.
- Report templates are stored as word documents, using a jinja-like template format.
- An unlimited number of buckets can be tied to a report and used to render it.
- Rendered reports can be downloaded as docx or pdf.
- First report template “AFIs and Strengths Report” added to platform.
- Added “artifact” storage capabilities.
- Can now create, update, and delete media artifacts.
- 3 new tables added – report, artifact, and bucketreports.
- Various improvements to Automations.
- Created a tie between Automation Configs and Model Versions.
- During upgrade, existing Automation Configs will be tied to the latest version of the model their parent Automation Config Template is associated with.
- When calling the automation route, the Model Version tied to the Automation Config is now used to predict the fields, which may not be the latest version.
- Test Runs are also processed and displayed based on the tied Model Version.
- Automation Configs can now be configured to prohibit duplicate automation. If the automation route is called with a record uid that has been previously automated by the Automation Config Template, an HTTP 422 response is returned.
- Data from a Dataset can now be fed directly to an Automation Template from within the platform by performing an AutoFlow run on a Dataset. Previously an outside script was needed to call the automation api.
- Automation Data Records can now be retrieved with the current ground truth Source Data Record.
- Created a tie between Automation Configs and Model Versions.
- Various enhancements to Analytics and Datasets.
- Improved handling of scoring runs, especially when errors are encountered during scoring. A scoring run can now be canceled by calling the route /datasets/{datast_id}/cancel-score.
- Increased Dataset description maximum length from 300 characters to 1,000.
- Platform now ships with a demo Dataset (NRC Event Reports 2019-2020), Analytic Buckets, Automation Template, and associated examples.
- Fixed bug where the unique column field would only be stored the first time data was uploaded to a Dataset.
- Added benchmark proportion and relative differences to analytic results when a benchmark dataset is configured
- When downloading a raw predictions csv for an Analytic, columns used for model inputs and analytic inputs are now included in the download.
- Added support for an unlimited number of arbitrary split dates in an Analytic (previously only one was supported).
- Misc fixes and improvements.
- Upgraded docker image base to ubuntu:22.04.
- Removed several old source code files that were no longer being used.
- Upgraded target python version from 3.9 to 3.10.
- Improved error handling for a variety of different issues
- Fixed bug where a corrupted model wheel file could be saved in file cache. MRE will clear the cache and attempt to redownload if a corrupted file is encountered.
v1.5.5
Patched various security vulnerabilities, including:
- Forced TLS version >= 1.2
- Fixed various content headers
- Enabled javascript strict mode on config.js
- Updated np_app_proxy to v0.0.3
v1.5.4
Updated MRE to v0.4.5
- Added a route to retrieve prediction overrides directly
- Patched various python package vulnerabilities
v1.5.3
- Scored predictions override now in preview
- Dataset viewer now has filtering
- Enhancements to application authentication administration
- Misc bug fixes and error handling improvements
Updated frontend to v0.3.1
- PREVIEW: Added ability to view and override scored predictions
- Navigate to override page by clicking on a record in the dataset viewer
- Users can view any predictions for any model a source data record has been scored on
- Users can override any prediction confidence with a value between 0 and 1
- Users can set all non-overridden values for a record to 0 confidence by using the “Set Remaining to No” button
- Application authentication enhancements
- Added ability for admins to manually update “email_validated” for users on the user page
- Added ability for admins to generate a password reset link on the user page
- Filters added to dataset view
- Users can now filter the records being viewed in the dataset viewer by filtering on any column
- Multiple filter conditions can be added
- Updated node.js to LTS version 16.18
Updated MRE to v0.4.4
- Prediction overrides
- New ability to override scored data record predictions via route /datasets/{dataset_id}/override_predictions/{source_uid}/{model_version_id}/{model_label_class_output_name}
- Added ScoredDataRecordOverrides table
- Added “override_order” and “override_confidence” columns to scored data record predictions that are updated when overrides are made
- Added route /datasets/{dataset_id}/prediction_details/{source_uid}/{model_version_id}/{model_label_class_output_name} to get latest predictions
- Dataset filters
- Added support for filters to /datasets/{dataset_id}/records route
- Cleanup logically deleted datasets and associated records
- Added API route /datasets/permanent-delete-datasets to clean up logically deleted datasets
- Added check to not allow a logical delete of a dataset when it is still being referenced by an automation config template
- Added check to not allow a logical delete of an automation config template when it is parent to one or more other automation config templates
- Better support for app authentication setup
- Added route /auth/password/reset-request-token/ to produce a password reset link
- Updated route /user/update-email-validated/ to set email_validated attribute on users to true or false
- Misc
- Improved performance and memory usage on setup of large scoring jobs by only storing scoring status in shared memory instead of the entire source data record
- Improved error handling when duplicate records found in source data record sync
- Added additional error handlers to improve error messages
Updated Nuclearn PlatformReleases
- Increased gunicorn worker timeout to 7,200 seconds from 240
- Improved upgrade script to fix issues upgrading within patch versions
- Improved nuclearn-save-images.sh to use pigz if installed to decrease zip file creation time
Updated Dependencies
- np_app_db updated to version 0.0.3 to patch vulnerabilities
- np_app_proxy updated to version 0.0.2 to patch vulnerabilities
- np_app_storage_service updated to version 0.2.1 to patch vulnerabilities
- modelbase updated to version 0.3.2 to patch vulnerabilities
v1.5.2
Updated MRE to v0.4.2
- Fixed bug where analytic csv export was not returning a stream
v1.5.1
Updated MRE to v0.4.1
- Fixed bug where only one model would deploy on restart
v1.5.0
Updated Frontend to v0.3.0
- Release of Cluster Analytics
- Added Cluster Analytics to the dataset analytics screen.
- Ability to select a specific slice and time period for viewing.
- Interactive cluster analytics displaying labels (PO&C codes), the number of records associated with the label, and a “heat” color based on a weighted average of key metrics.
- Interactive cluster label locations are based on semantic similarity of the labels and the records within those labels.
- Ability to click on one or more labels to view details, including a time series chart, slice comparison, and specific records.
- Added “Buckets” (preview).
- Buckets are a specific selection of labels for specific analytic options.
- Buckets have a name and description.
- Ability to navigate directly to cluster analytics with associated analytic parameters and selected labels by clicking the “Analyze” button on the Bucket list.
- Ability to view all available buckets for selected analytic options from the Cluster Analytics pane.
- Major updates to the dataset analytics screen.
- Default options updated for most analytic options to match recommended values.
- Default view of analytic options made much simpler, with only the most commonly adjusted options seen. Advanced options can be selected with a toggle button on the top right.
- Added ability to select “Benchmark” datasets in analytic options. Benchmark values are retrieved from the provided dataset and joined onto the analytic results via the predicted label.
- Less commonly used analytics viewing options have been consolidated behind an “Additional Analytics” dropdown button.
- Significantly reduced need to pass around all analytic parameters for every analytic call, instead using the “Analytic” server-side persistence.
- Added Cluster Analytics to the dataset analytics screen.
- CAP Automation Minor Enhancements
- Added automation configuration integration tab with dynamically generated code examples.
- Added cumulative time period option to automation configuration KPIs.
- Added the ground truth data record details to the automation configuration Audit table.
- Automation configuration Audit table now displays accuracy, automated, and manual sample as three separate columns.
- Misc Updates
- Reorganized sidebar navigation to separate Admin (Models & Users), Analytics (Buckets & Datasets), and Products.
- Added sorting to most dropdown selectors.
- Added option to log inference request data to a dataset when mapping a dataset to a model version.
Update MRE to v0.4.1
- Version 3 of the WANO PO&C Labeler released
- New Neural Network architecture implements latest state of the art techniques.
- Improved accuracy and better coverage across a wider variety of PO&C codes.
- Major updates to analytics
- Added ability to include a “benchmark” value in stats analytics. The benchmark value is retrieved from a dataset, and joined onto the stats analytics results by matching predicted labels with a column from the benchmark dataset.
- Added ability when running stats analytics to split time periods by an arbitrary date instead of just a week/month/quarter/year.
- Stats analytics parameters are now persisted server-side as an “analytic”. This allows the frontend and other integrations to reference analytic parameters by a single ID rather than having to track and pass over a dozen different analytic parameters.
- New “Bucket” functionality. Buckets track a set of selected labels and other parameters for an analytics, as well as a name and description. Added ability to create, update, delete and view buckets.
- New route to get the source data records related to an analytic and specific label selections.
- Added a route to produce a list of WANO PO&C codes and their descriptions as well as x/y coordinates for cluster mapping.
- Quality of life improvements to dataset management
- Added ability to log the data sent to an “infer” request for a model to a dataset. When datasets are mapped to a model version, the option to log infer requests to that dataset is now included.
- The field selected as the source UID when uploading data to a dataset is now saved.
- Update MRE to support multiple processes/workers running at the same time. This is the most significant performance improvement to MRE so far.
- Updated connection pooling to be process specific.
- Updated default number of workers to 8 from 1.
- Updated model version deployment on startup to be multi-process safe.
- Refactored dataset model scoring to be mutli-process safe.
- Misc updates
- Upgraded target python version from 3.8 to 3.9.
- Added more detailed exception handling in various places.
- Added custom exception handlers and handle uncaught custom exceptions during route calls. This should reduce the number of nondescript HTTP500 errors.
- Added “cumulative” time interval option to automation KPIs.
- Added a check to ensure the database and mre are operating in UTC.
- Deprecated the following routes:
- /models/{model_id}/version/{version_number}/config/
- /models/active
- /stats/
Misc
- Updated np_app_storage_service to version 0.2.
Come visit us at nuclearn.ai, or follow our LinkedIn page for regular updates.