Nuclearn v1.7 is our quickest release yet, coming just two months after v1.6! The theme of this release is responding to and delivering on our customers evolving needs. In this version we’ve focused on the integration of our platform with a nuclear site’s platform, user interface redesign, and optimization of our software for increased performance.
Seamless Integration of Customer Platform to Nuclearn
Over the last year, we have observed a challenge facing several customers: data integrations were taking time and money to develop and deploy, and would sometimes delay projects. To further improve the value to our customers, this release simplifies that integration process between the Nuclearn platform and external application databases. We now have the functionality to extract and transform a site’s data from various databases and load them into Nuclearn data models.
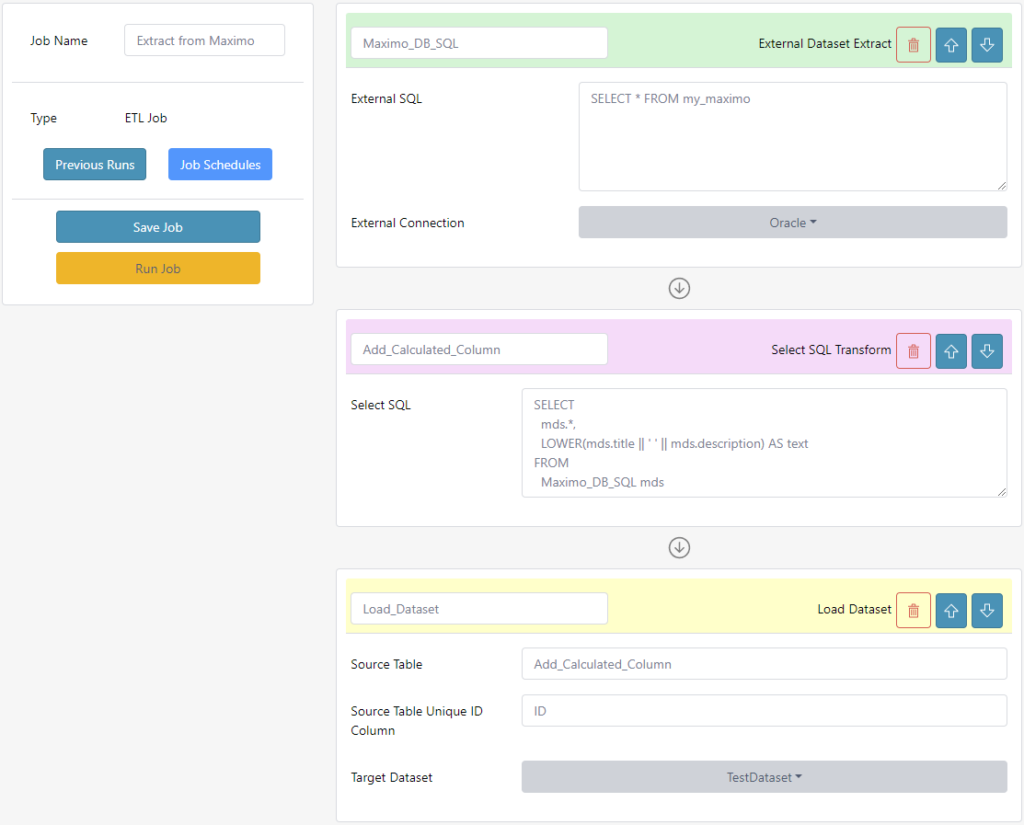
Customers can easily process and manipulate their data through the new job functionality. The feature allows the creation of multi-step jobs to extract, transform and load data into and from internal and external datasets. Administrators have the flexibility to execute jobs manually or schedule them to run automatically. They will also have access to job status and logs view. Additionally, the ability to create write back integrations has been added to our roadmap.
User Interface Redesign
One of the major changes in v1.7.1 is simplifying the user experience for common tasks. In previous releases, some common tasks involved dozens of clicks across multiple screens, making it difficult and unintuitive for users. Our new design features a more task-based approach, where key tasks can be performed on a single screen.
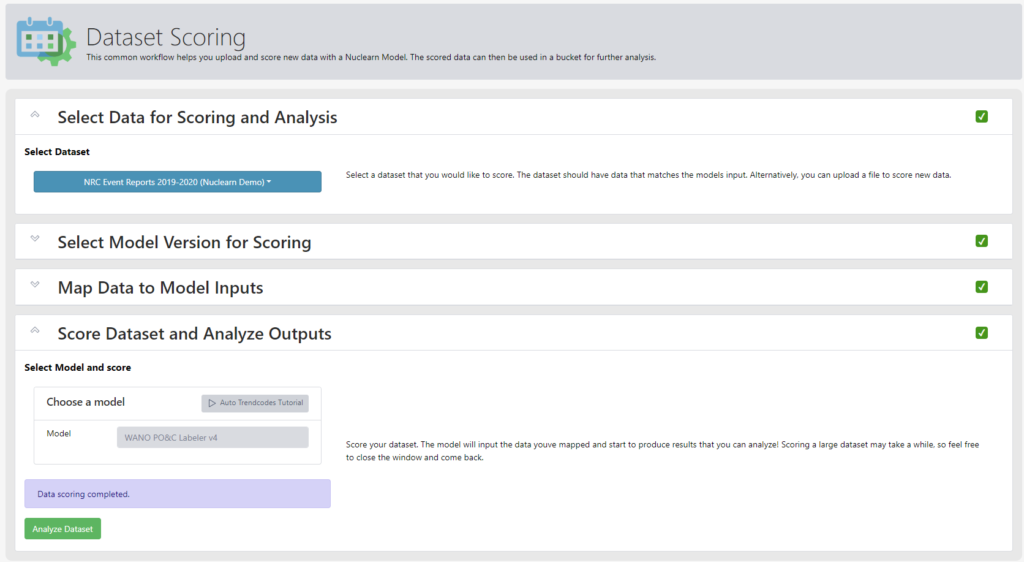
The first example of this new approach is the new functionality for Dataset Scoring. Users are now walked the through the step-by-step process needed to score and analyze a dataset from scratch on a single screen, including selecting a dataset, choosing the appropriate Nuclearn AI model, mapping data to the model inputs, scoring the dataset and analyzing the outputs.
We’ve also improved the layout on various menus and tables across the platform. Users should see more information about key objects, and not have tables load wider than their screens.
Optimization to increase performance
In v1.7 Nuclearn’s AI models have been optimized! Our new models have a 10x model size reduction and 2-5x speedup of per record dataset scoring. while maintaining their accuracy. What does this mean for our customers? This results in a faster installation of our products and also increased speed on the transfer of a site’s data to our platform. These new models are not activated by default to give customers time to test and convert existing processes to the new models, but we strongly encourage enabling them as soon as you can!

Nuclearn Platform Release Detailed Notes
V1.7.1
- Refinements to the Extract-Transform-Load (ETL) job user interface and validations
- Improvements to the Cron job scheduling page appearance
- Early release of the Dataset Scoring wizard. Home page defaults to the wizard page now
- Action buttons now display the icon only, and expand to display text on hover
- Misc frontend appearance tweaks
Updated frontend to v0.5.2
- [Bug Fix] Missing Hamburger button and collapse/expand icon icon
- [Bug Fix] Clicking on a dataset row that has a nested json/detail data displays object instead of value
- [Bug Fix] Name columns are too narrow and truncate text most of the time in data tables
- [Bug Fix] Attempting cron job scheduling displays Undefined error
- [Bug Fix] Job schedules breadcrumb in the header is wrong
- [Bug Fix] Load dataset job step defaults to unique id column of first dataset in the dropdown
- [Bug Fix] Having Load Dataset as last step in an ETL job allows empty names to be saved
- [Bug Fix] Cannot create a job until at least one external connection gets created
- [Bug Fix] Error encountered during step – Dataset id 0 not found
- [Bug Fix] Cannot create a new report with only one bucket present
- [Bug Fix] Unable to navigate to Job Schedules page
- [Bug Fix] Run job notification message inconsistent
- [Bug Fix] Modify existing and create new job allows the save with an empty name
- Added early version of dataset scoring wizard that guides the user through various steps needed to score a dataset
- Frontend ETL job step failure error display
- Empty name validation error in job step not specific enough
- Datasets table display on some screen sizes displays horizontal scroll bar
- User session is now shared across web browser tabs so frontend can be used from multiple tabs at the same time
- Change secondary button color to make it easier to distinbuish between disabled and clickable buttons
- Enable modifying model version config and model base image
- Cron job scheduling UI now guides the user through various options
- Previous job runs page button alignment
- Allow updates to External Connection name
- Clicking Run from Update Job screen now executes the job right away and no longer needs two clicks
Updated MRE to v0.6.1
- Support running a record through the automation route when it is posted to the upsert source data record
- When deleting a job ensure scheduled jobs are deleted so that we dont have orphans
v1.7.0
- Extract-Transform-Load (ETL) job and scheduling functionality now in preview
- Extract and transform data from SQL Server and Oracle databases and load into Nuclearn datasets
- Setup automatic job execution on a recurring schedule
- Simplify integration between Nuclearn and external application database
- Brand new model base runtime environment shipped in addition to the traditional one
- Enables up to 10x model size reduction and 2-5x speedup of per record dataset scoring
- Scheduled to completely replace traditional model base runtime environment in version 1.9
- Shipped new versions of WANO and PO&C models based on new model base runtime environment
- New models are undeployed by default to give customers time to test and convert existing processes to new models
- Enabled support for multiple runtime environments and allowed per model environment assignment
- Enabled binding of each Nuclearn user role to separate Active Directory user group
- Other misc updates
Updated frontend to v0.5.0
- Job functionality now in preview
- Added Jobs link to sidebar (preview)
- Allows creation of multi-step jobs to extract, transform and load data into and from internal and external datasets
- Jobs can be executed manually, or scheduled to run automatically
- Job status and logs view added
- Added External Connections to the sidebar
- Allows Nuclearn to connect to external databases
- Current support for Oracle or SQL Server databases only
- Added Jobs link to sidebar (preview)
- Azure Active Directory Integration Improvements
- Rerun azure login flow and clear nuclearn Authz token cache during the Azure AD login procedure or HTTP 401 error from the API
- Invalidate react query when nuclearn token is expired
- [Bug fix] Log off fails under some circumstances
- Misc updates
- [Bug fix] Hamburger button on collapsed left panel does not display full size panel on click[Bug fix] Visualization is spelled wrong on the buckets page[Bug fix] Dataset and bucket lists render poorly on certain screensizes[Bug fix] User profile dropdown opens under the automation template toolbar[Bug fix] Infinite loader on datasets is missing records on displayChange secondary button color to make it easier to distinguish when button can be clickedMake undeployed models collapsed on Models pageDisable the ability to create new versions for pre-installed modelsOnly run isUTF8 validator on csv upload when file is below a certain size, display warning that file won’t be validated otherwise.Improved footer appearance
- Updated MRE to v0.6.0
- Extract-Transform-Load (ETL) job and external connection functionality (preview).
- Added APIs to check the status of a job
- Added APIs to run a job
- Added APIs to store a job
- Added APIs to to store external connections
- Added job scheduler component
- Added APIs to create, update or delete job schedules
- Enabled support for multiple runtime environments and allowed per model environment assignment
- Added API to update model versions
- Model versions can be updated to use a different model base runtime environment
- If model base runtime environment is not specified, most current one is picked by default
- All existing model versions will be updated to use traditional model base runtime environment
- Misc fixes and improvements
Misc Updates
- Updated database to PostgreSQL 13.8