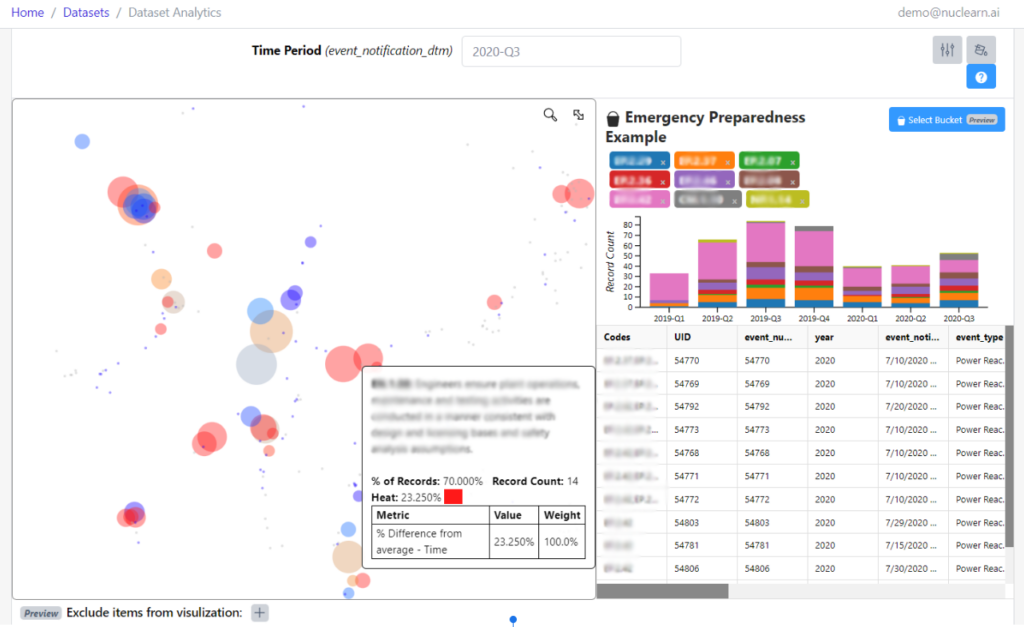
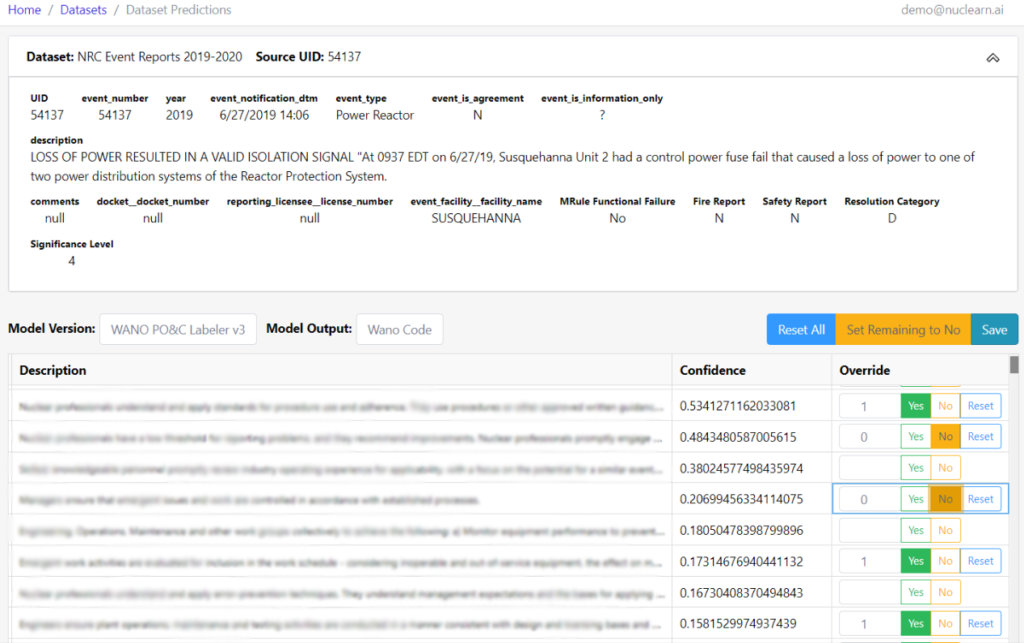
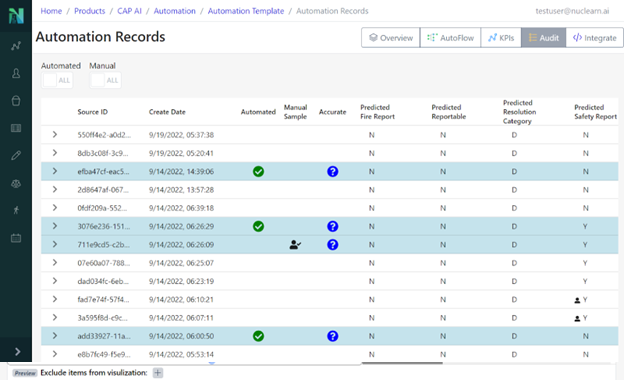
Few areas in nuclear engineering are as foundational—or as complex—as 10 CFR 50.59. Whether evaluating a plant modification, equipment upgrade, or digital system implementation, the question remains the same: Does this change require prior NRC approval? For decades, answering that question has required long hours of research, interpretation, and justification—often across fragmented guidance, buried precedent, and aging internal documentation.
With the launch of Agentic 50.59 Workflows, Nuclearn is changing that. Part of our Engineering AI solution suite, these new 50.59 capabilities bring nuclear-specific AI directly into the licensing workflow—helping engineers and licensing professionals move faster, with more clarity, and without compromising traceability or safety.
“Every minute spent searching through fragmented documentation is a minute not spent on what matters most—safe, reliable nuclear operations,” said Brad Fox, CEO and Co-Founder of Nuclearn.
“Our 50.59 solution transforms weeks of manual research into minutes of AI-powered analysis, giving engineers the confidence to move forward with complete regulatory clarity. This isn’t just about efficiency—it’s about empowering the nuclear workforce to focus on innovation while maintaining the highest safety standards.”
The Problem: Complex, Manual, and Costly
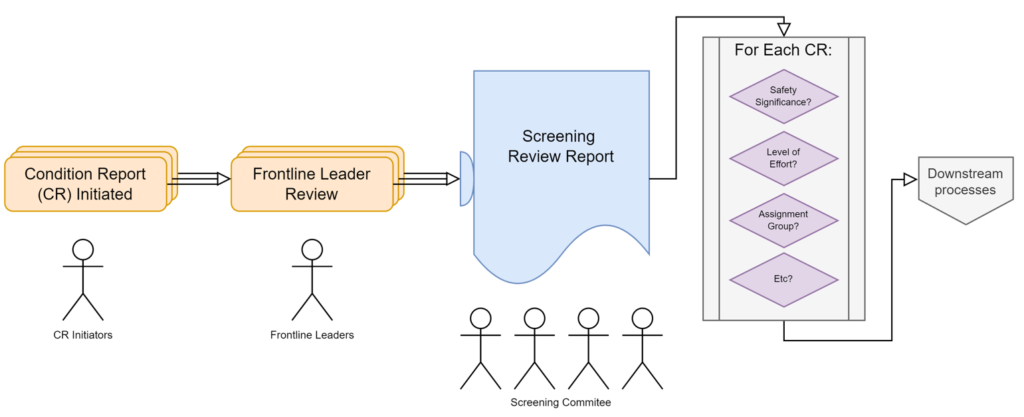
The traditional 50.59 process relies heavily on institutional memory, document repositories, and scattered evaluations. Teams tasked with screening a proposed change must often:
- Manually search through decades of precedent
- Cross-check NRC guidance, internal evaluations, and site-specific bases
- Align interpretations that vary between individuals or sites
- Spend valuable engineering time on documentation—not decision-making
This approach isn’t just inefficient. It slows innovation, increases the risk of misinterpretation, and puts undue burden on engineers who should be focused on solving real-world problems.
The Solution: Agentic 50.59 Workflows
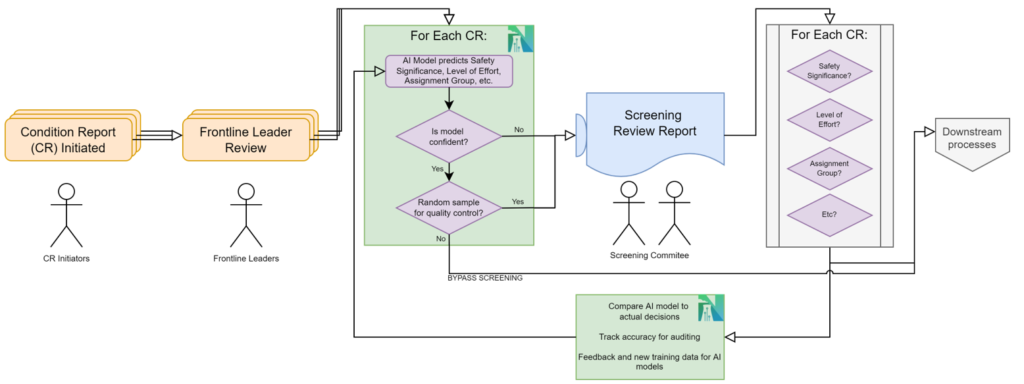
With Agentic 50.59, Nuclearn introduces a transformative way to evaluate whether a proposed change impacts the facility’s licensing basis. This isn’t a form fill or a static checklist—it’s a dynamic, interactive workflow powered by AI built for nuclear.
Here’s how it works:
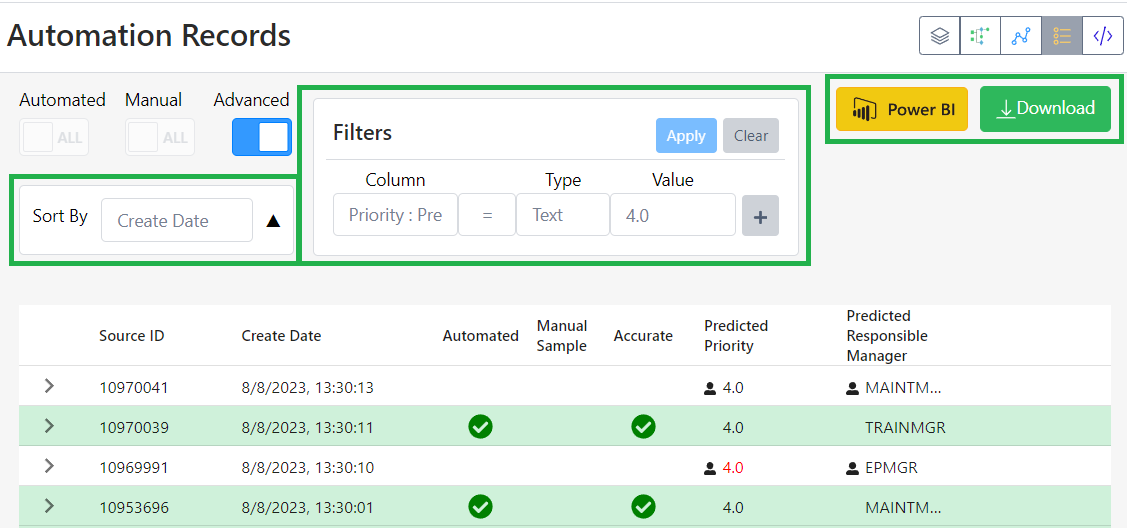
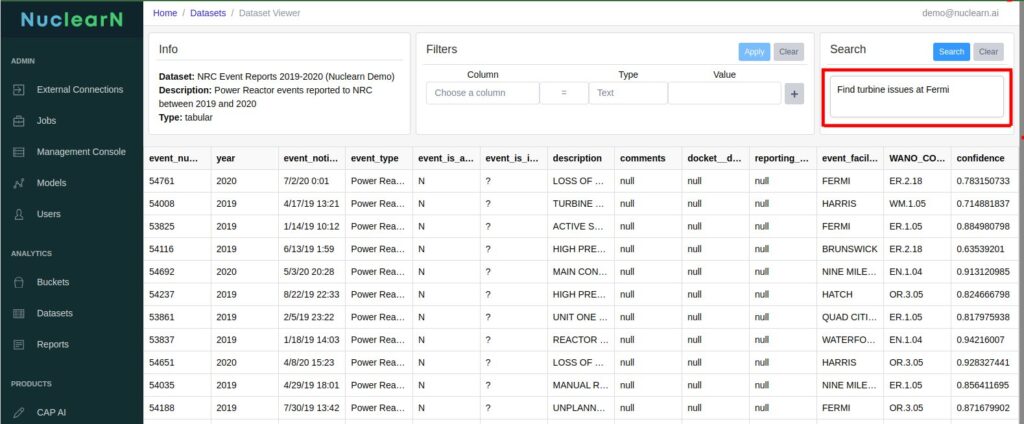
- 🧠 Semantic Search: Quickly surface relevant past 50.59 evaluations, NRC precedent, and guidance based on meaning—not just keywords.
- 🔗 Cited Authority: Automatically reference regulatory sources, site-specific licensing bases, and industry standards to support decision-making.
- 💬 Conversational Interface: Ask detailed questions and receive context-aware responses from an AI trained on real nuclear data.
- 📁 Traceability: Capture every step of the evaluation process, including justification, sourcing, and reasoning—ready for audit or peer review.
The result? A workflow that reduces hours of research into minutes of meaningful analysis, and one that scales with your team—whether you’re evaluating a single change or hundreds during an outage or upgrade window.
More Than a Feature—It’s a Foundation
Agentic 50.59 is more than just a search tool or a digital form. It’s a new foundation for how engineering teams can tackle complex licensing workflows using purpose-built AI.
It serves as the cornerstone of Engineering AI, a larger solution suite designed to support engineering, QA, and licensing teams with smarter tools for repetitive, high-stakes tasks.
Other key products in the Engineering AI suite include:
📋 Reportability Screener
Quickly pre-screen CRs and proposed changes against NRC reporting criteria. Offers rapid insights into whether a condition may require reporting—reducing uncertainty and speeding up response.
🔎 CR Smart Search
AI-driven search that allows users to explore past condition reports based on similarity, outcome, and resolution—ideal for CAP, QA, and engineering teams trying to learn from precedent.
🧾 Document Comparison Tool
Compare procedures, licensing documents, design packages, or evaluations side-by-side. Highlights structural and content differences for easier review, traceability, and QA.
Together, these solutions create a connected workflow environment that supports end-to-end engineering decisions—especially in high-impact areas like plant modifications, configuration control, and licensing justification.
Built for What’s Next
Nuclearn built Agentic 50.59 in partnership with top utilities and engineering firms—teams who know what it means to screen hundreds of modifications in a matter of weeks during an outage or digital upgrade.
They asked for a solution that could:
- Reduce the manual burden of research
- Help newer engineers ramp up faster
- Preserve institutional knowledge
- Deliver fast, consistent results that hold up to regulatory scrutiny
And that’s exactly what Engineering AI delivers.
Who Benefits?
The release of this product comes at a critical time for the industry. Many plants are navigating:
- License renewal and extension projects
- Power uprates and equipment modifications
- Aging management strategies
- Fleet-wide standardization of licensing practices
In all of these efforts, 50.59 plays a defining role. Nuclearn’s solution doesn’t remove engineering judgment—it strengthens it with data, precedent, and intelligent workflows that match the pace and complexity of the industry today.
Smarter Doesn’t Mean Riskier
At Nuclearn, we know that in nuclear, speed means nothing without safety. That’s why the Agentic 50.59 workflows are built with Part 810 compliance, on-premise deployment options, and full traceability baked in from the start. You get efficiency, yes—but never at the cost of oversight, documentation, or regulatory alignment.
See It in Action
The Agentic 50.59 capability is now available as part of the Nuclearn Platform and can be demoed live with your engineering or licensing team.
Whether you’re a utility preparing for your next project window or an EPC firm supporting client upgrades, this is your chance to see how AI can meaningfully improve your engineering outcomes—without changing your standards.
📅 Schedule a live demo
🌐 Explore Engineering AI at: www.nuclearn.ai
Final Thought
Modernizing 50.59 isn’t just a nice-to-have—it’s essential to nuclear innovation, safety, and performance. With Agentic 50.59 Workflows, Nuclearn is giving engineers what they’ve long needed: a faster, smarter, and more transparent path to confident licensing decisions.
Because real modernization doesn’t start with a new form. It starts here—with the power to ask better questions, find better answers, and act with clarity.
Trusted by Nuclear. Built for Engineers. Powered by Nuclearn.




 .
.