
In an effort to support a wider variety of implementations and make Nuclearn even easier to deploy, earlier this year we embarked upon an effort to make the Nuclearn platform directly compatible with Kubernetes via Helm. While we have worked with Kubernetes extensively in the past, and we’re very comfortable in a k8s environment, a Kubernetes port is no trivial task. It took us a few weeks longer than expected to work out all the kinks, but learned quite a few things along the way. We are happy to have included Kubernetes support as part of v1.4, and share some of our insights in our first technical blog post!
An “Easier” Path
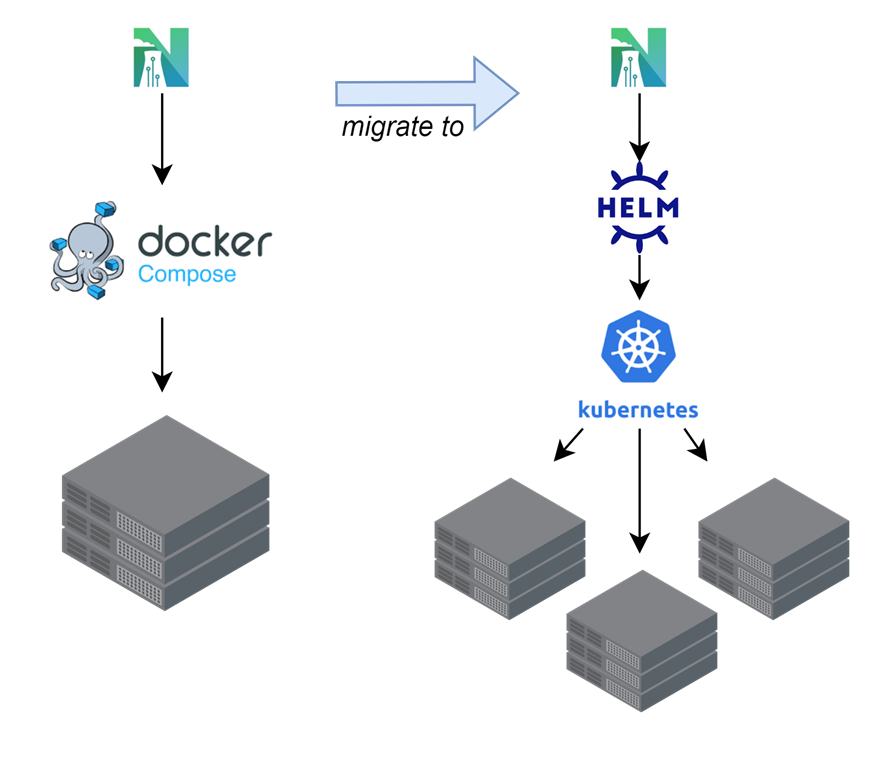
Luckily for us, the Nuclearn platform has been containerized via Docker from the very beginning. Our first deployments leveraged Docker Compose on a single VM, and the transition from Docker Compose to Kubernetes is certainly less of a lift than from a non-containerized application. Our approach to porting the application from Docker Compose to Kubernetes was fairly straightforward:
- Set up a Helm chart for the Nuclearn platform
- Set up subcharts for the individual services
- Configure each sub service as a deployment resource, and configure as closely to our Docker Compose entries as possible
- Debug until it works!
Before we could do that however, there was some refactoring of core services we needed to do…
The Big Refactor: Model Deployment
One of the biggest challenges with the move to Kubernetes was handling model deployment. Deployment of AI models is an essential feature to an applied AI platform and was one of the first features we developed. Nuclearn previously deployed AI models by interacting directly with the Docker API to dynamically deploy containers, set up networking, copy over model files to the container, and spin up the model serving services. While running model containers directly on a Kubernetes host might work, this approach would not be ideal, and required us to rethink and refactor how we handle model deployment.
First, we refactored all model deployment operations in our FastAPI deployment into a new “Model Orchestration Interface”. This allowed us to abstract away implementation details of model deployment into backend-specific classes. As a fringe benefit, this would make it far easier to support additional model hosting backends in the future (i.e. TensorFlow Serving, Nvidia Triton server, etc.).
Next we needed to update our model deployment containers to be able to retrieve model files from the Nuclearn Platform via API calls, instead of the original approach of pushing the model files to the containers as they spun up. This had its own challenges, and eventually progress ground to a halt. The model file downloads from the API were far too slow, taking several minutes to transfer a 100 MB file. After investigating, we discovered that using the FileResponse class instead of the StreamingResponse class in FastAPI resulted in a 10x improvement in file download speeds on large files.
from fastapi.responses import StreamingResponse
...
# This is very SLOW
return StreamingResponse(
filestream,
media_type="application/octet-stream",
headers={
"Content-Disposition": "attachment; filename="download.tar.gz"'
},
)from fastapi.responses import FileResponse
...
# This is much faster
return FileResponse(
filestream,
media_type="application/octet-stream",
headers={
"Content-Disposition": "attachment; filename="download.tar.gz"'
},
)Finally, we needed to build our own model orchestration drivers for Kubernetes. We elected to build a Kubernetes deployment on the fly instead of deploying pods directly via the Kubernetes API. This ended up being a lot easier to program (dynamically generate .yaml files and run a kubectl apply), and allowed us to retain native automated horizontal scaling of model serving in Kubernetes.
Networking Switch?
When deploying via Docker Compose, we were using a mix of Traefik for reverse proxy operations and docker networking for inter-container communications. Things had gotten a bit convoluted since the original release, as many of our customers required us to use Podman instead of Docker (there are several blog posts worth of lessons learned from that port alone). As a result, we ended up needing to use host networking for many of the services. As part of the process of moving to Kubernetes, we realized that the existing reverse proxy approach would not work, and we needed to determine the approach and tooling for our networking stack. We spent a fair amount of time deciding between updating our Traefik proxy for Kubernetes, migrating to nginx, or using native application networking via the Kubernetes cluster providers.

After quite a bit of deliberation, we ended up sticking with Traefik. This was for a variety of reasons, foremost being we were more familiar with using Traefik, and the Traefik project had continued to add a number of Kubernetes features that we thought would be helpful in the long term.
Traefik is awesome once you have things set up… but debugging during initial configuration is another story. Unfortunately the Traefik documentation is notoriously challenging (a quick google search will reveal many nightmares), and we certainly experienced this during our Kubernetes port. We initially wanted to use native Kubernetes Ingress resource definitions with Traefik annotations, but we found the Traefik-native IngressRoutes better supported, documented and much easier to configure. One of the key refactors to support Kubernetes was to switch from port-based routing to differentiate our frontend from our API, to path-based routing (e.g. https://nuclearn/api instead of https://nuclearn:49152). While it is possible using Kubernetes native Ingress, IngressRoutes were much easier, straightforward to configure, and worked well.
Helm – the Last Step
The last part of the Kubernetes port was setting up a helm chart to deploy the application. We elected to use Helm as the Nuclearn Platform is composed of several different services, and we wanted to centralize as much of the configuration and deployment as possible. Our Docker Compose deployment would use several different configuration files (at least one for each service), and we hoped that with Helm we could get that down to one configuration file for the whole application.
Helm debugging is quite interesting and ended up being a better experience than anticipated. Once you have your Helm workspace setup, you can “apply” the set of Kubernetes specs to a cluster with a Helm install or Helm upgrade command.
helm install nuclearn-chart nuclearn \
--values nuclearn/values.yaml \
--namespace nuclearnnamspace
# after running install, you update existing deployments with
helm upgrade nuclearn-chart nuclearn \
--values nuclearn/values.yaml \
--namespace nuclearnnamspaceThe install and upgrade commands essentially take a Helm workspace, the provided values and command line arguments, and generate a new Kubernetes yaml file on the fly. We found during debugging that it was very helpful (and quick) to generate and view this yaml file, as many of the bugs we found in setting up Helm were very easy to see in the “compiled” yaml. This could be done with Helm template command:
helm template nuclearn-chart nuclearn \
--values nuclearn/values.yaml \
--namespace nuclearnnamspace > debug.yamlOne unique challenge we faced was getting our authentication configuration to pass down from the nuclearn chart to our API subchart. Our API server uses it’s own yaml file, and we were using ConfigMaps to create the appropriate file in the container. Our ConfigMap definition for the API server (service name “mre”) looks something like:
### nuclearn/charts/mre/templates/mre-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: mre-config
namespace: {{ .Release.Namespace }}
data:
mre-config.yaml: |
appName: ModelRuntimeEngine
logLevel: {{ .Values.logLevel }} # debug or info
...We were able to default single parameters relatively easily (such as logLevel) by adding a default entry in the sub-chart values.yaml, and optionally overriding in the nuclearn chart.yaml with an entry like:
### nuclearn/charts/values.yaml
...
mre:
logLevel: info
...Unfortunately, our authentication provider configuration is a lot more than a couple parameters, and varies significantly by the authentication provider. As a result, we wanted to be able to define the whole “Auth” configuration in the nuclearn chart values.yaml, and inject that into the resulting ConfigMap. So our values.yaml file would end up having an entry like this:
### nuclearn/charts/values.yaml
mre:
Auth:
authMethod: "ActiveDirectory"
params:
# Secure LDAP (True/False)
secure: True
# IP address or domain name of your LDAP server.
provider_url: "ad.yourdomain.com"
#The port to use when connecting to the server.
# 389 for LDAP or 636 for LDAP SSL
port: 636
# Use SSL - should be true if port is 636
use_ssl: True
...And in our mre-config.yaml template, we initially tried adding this entry directly:
### nuclearn/charts/mre/templates/mre-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: mre-config
namespace: {{ .Release.Namespace }}
data:
mre-config.yaml: |
appName: ModelRuntimeEngine
logLevel: {{ .Values.logLevel }} # debug or info
Auth:
{{ .Values.Auth }}Unfortunately, this did not work! The result of the Helm template command looked like this:
### debug.yaml
...
mre-config.yaml: |
appName: ModelRuntimeEngine
logLevel: debug # debug or info
Auth:
map[authMethod:ActiveDirectory params:map[port:636 provider_url:ad.yourdomain.com secure:true use_ssl:true]]Helm uses the “go” programming language, and rather than injecting formatted yaml into template as we expected, it appears to be converting the go language object directly to a string! After some research, we discovered we could use the “toYaml” function to format the yaml before injecting it. After updating the template, we were confused when we got the following error when running “helm template”:
### nuclearn/charts/mre/templates/mre-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: mre-config
namespace: {{ .Release.Namespace }}
data:
mre-config.yaml: |
appName: ModelRuntimeEngine
logLevel: {{ .Values.logLevel }} # debug or info
Auth:
{{ .Values.Auth | toYaml }}> helm template nuclearn-chart nuclearn \
> --values nuclearn/values.yaml \
> --namespace nuclearnnamspace > debug.yaml
Error: YAML parse error on nuclearn/charts/mre/templates/mre-configmap.yaml: error converting YAML to JSON: yaml: line 17: mapping values are not allowed in this contextNeedless to say this was quite confusing. We spent a fair amount of time researching this error to eventually discover that the yaml was getting correctly generated, but that it was not injecting at the appropriate indentation level. The resulting mre-configmap.yaml ended up being invalid, resulting in the above error. We were finally able to get this to work by adding an indent command and trimming the first line:
### nuclearn/charts/mre/templates/mre-configmap.yaml
kind: ConfigMap
apiVersion: v1
metadata:
name: mre-config
namespace: {{ .Release.Namespace }}
data:
mre-config.yaml: |
appName: ModelRuntimeEngine
logLevel: {{ .Values.logLevel }} # debug or info
Auth:
{{ .Values.Auth | toYaml | indent 6 | trim }}### debug.yaml
...
mre-config.yaml: |
appName: ModelRuntimeEngine
logLevel: debug # debug or info
Auth:
authMethod: ActiveDirectory
params:
port: 636
provider_url: ad.yourdomain.com
secure: true
use_ssl: trueIt finally worked! With this done, we were able to centralize almost all configuration for the Nuclearn platform in nuclearn/values.yaml.
Concluding our Journey
While we originally hoped the Kubernetes port would take about a week, it ended up taking closer to three. Cluster setup, debugging, and needing to refactor core parts of the platform contributed to the extra time, but we learned quite a bit along the way.
Besides the value this update brings to our customers, there were numerous internal advantages to Kubernetes that we discovered. We utilize continuous testing using Cypress, and the ability to quickly provision and scale test deployments of Nuclearn will make our tests quicker, allowing us to have a larger, more in depth automated test suite. Additionally, we anticipate an improved customer installation experience as installation and upgrades are easier and faster. Overall we are quite happy with the Kubernetes port, and excited to bring this addition to the Nuclearn platform!