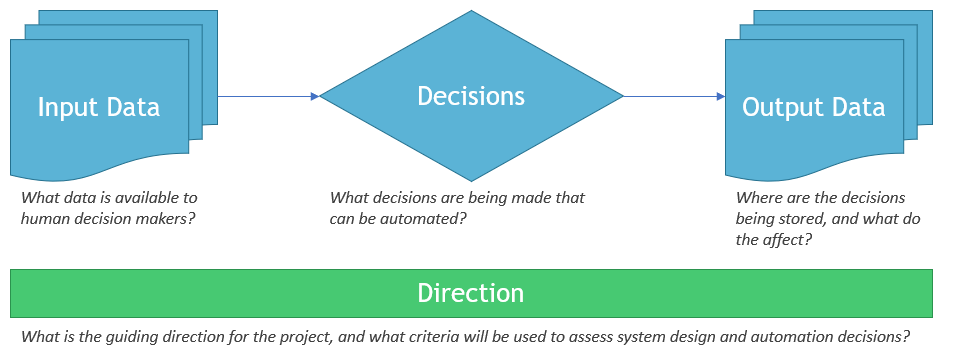
General
Do you deploy on-premise or on cloud?
Nuclearn can be deployed on-premise, on private cloud, or as hosted SaaS on GovCloud. For customers that want us to do hosted SaaS, we do include a small price increase to support cloud hosting costs.
Are there any hidden costs with using Nuclearn?
The subscription license fee includes the software license, model fine-tuning, installation, support, training, and software upgrades. We don’t charge additional professional service fees or change orders to get our software up, running and automating. The only professional services we charge are if Nuclearn is contracted to develop and maintain highly customized integrations.
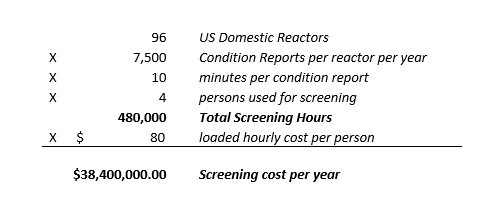
AutoCAP Screener – Automated Corrective Action Program Screening
What machine learning technologies are used to automate screening?
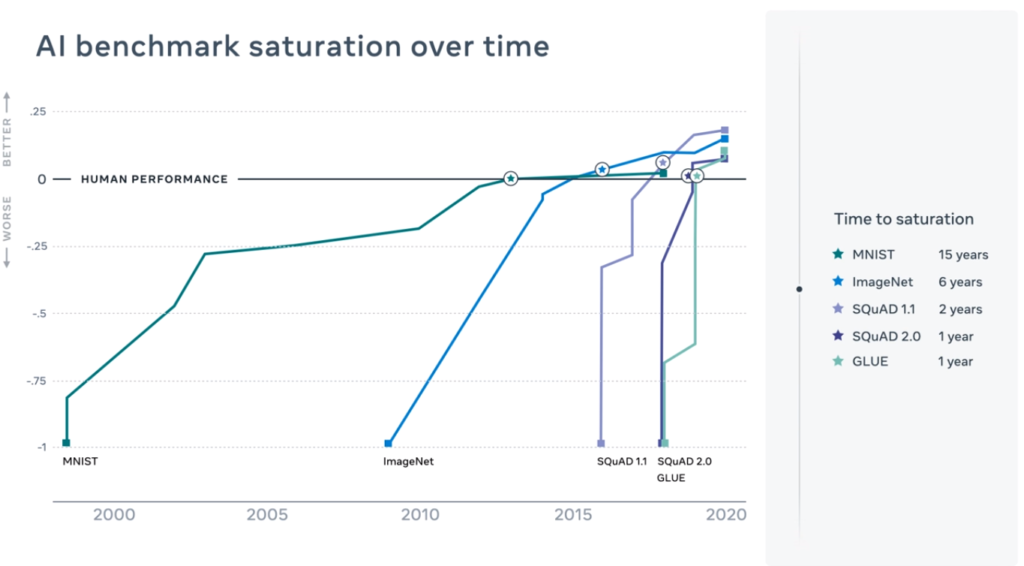
As of 2023, Nuclearn uses a type of deep neural network commonly known as a “Large Language Model”. These models deliver state of the art performance on a wide range of machine learning tasks, especially those with unstructured input (e.g. condition report descriptions). AI and machine learning are quickly evolving, and Nuclearn commonly releases updates to out of the box and customer specific models to improve performance.
How do you train the models?
Training these models is very resource intensive, and requires specialized hardware. For model fine-tuning, we ask our customers to share with us a representative sample of condition report data. We then fine-tune our Nuclear-specific models on that data to learn site-specific terminology and patterns in order to deliver the best performance. The fine-tuned models are then deployed on-premise or on cloud as needed.
How much data do the models need to train?
As much as you can provide! Model performance improves with additional data, even if older data is of a poor quality or differs from current screening processes. >10,000 condition reports spanning at least one refueling cycle is typically sufficient.
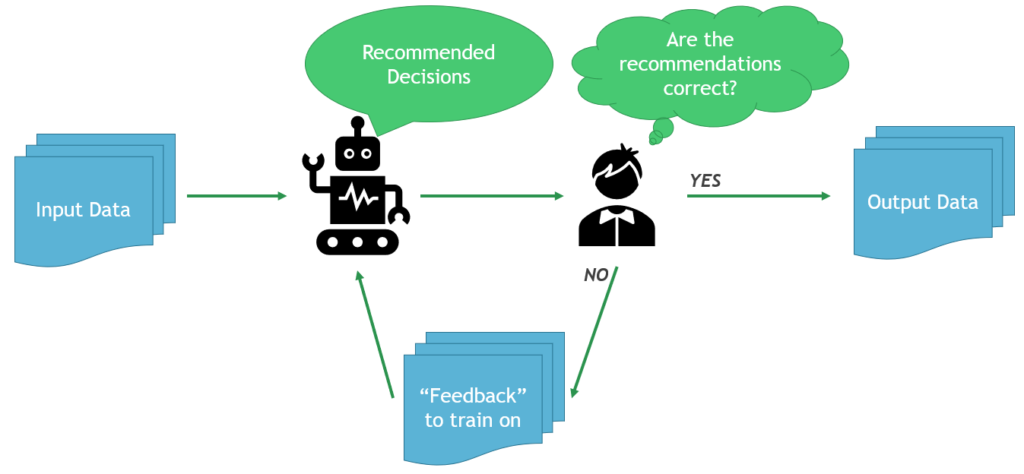
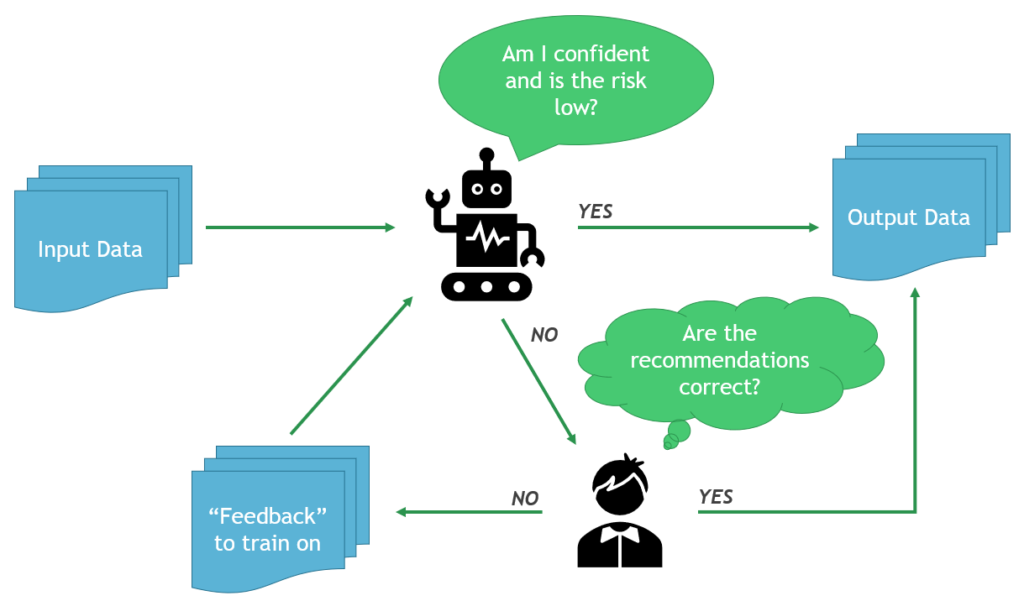
How does the system choose what to automate?
When Nuclearn’s models process a new condition report, they make predictions for all screening decisions (e.g. Condition Adverse to Quality, responsible group, etc.), and provide a confidence value for each decision. These predictions and confidence values are compared to the current automation configuration, and if any of the decisions do not meet the confidence threshold, the condition report will not be automated.
How does the system track accuracy?
Every condition report processed by Nuclearn is added to an audit trail, including all the information provided to Nuclearn, the model that was used, the automation configuration, and the model output. After the condition report has been fully processed, the “ground truth” data is sent back to Nuclearn to calculate accuracy and system performance.
To track accuracy on automated records, a configurable randomly selected proportion of condition reports that would’ve been automated are instead sent for manual review. This single blind sample-based approach allows Nuclearn to continuously estimate performance of automated records without requiring manual review of all records.
Can we control the automation configuration?
You have full control over the automation configuration, including what decisions to automate, desired levels of accuracy, and manual control sample rates. You don’t need to contact Nuclearn to have these changed, although we are happy to assist.
Some of our condition reports are cryptic or poorly worded. How are these handled?
This is one of the important reasons that we fine tune our models on your site’s data. Different utilities have different acronyms, terminology, “style”, and variability in their condition reports. The fine-tuning process allows the models to learn these patterns. If a particular condition report is very vague or poorly worded, we typically see the models produce a low-confidence prediction that doesn’t get automated.
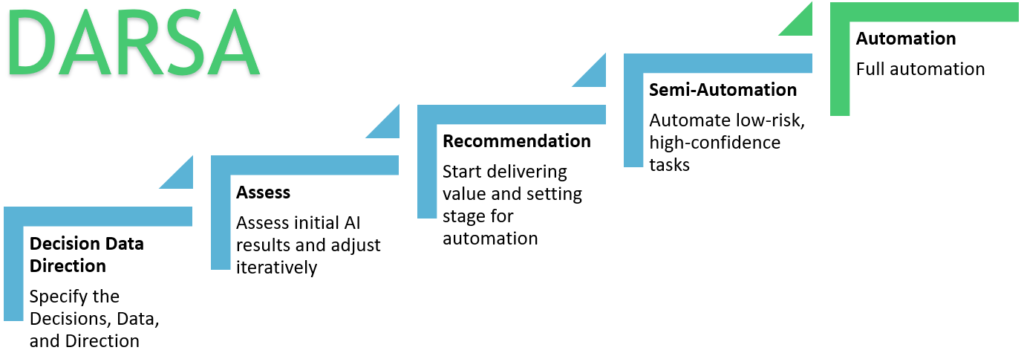
Do you have to start with high levels of automation on day 1?
We recommend that customers do a period of time in “full recommendation mode”. In this mode, condition reports are fed through the automation pipeline and tracked, but no records are “automated”. This allows the site to gather performance data and gain comfort with the process before automating. After deciding to automate, we recommend customers ramp up automation by starting with conservative configurations with high manual sample rates, and incrementally increasing automation rates.
Evaluator – Automated Trend Coding & Analysis
How does automated trend coding work?
Nuclearn provides a model that can take any provided text and predict that certain trendcodes are applicable. This model can be applied to any text, but typically works best with condition reports. This model can be used to predict these codes for a single example, or to score many records at once and save the predictions for later analysis.
What trendcodes are available?
The current model provides predictions for the industry standard WANO Performance Objectives and Criteria (PO&C). The next iteration of the model (2023 Q2 or Q3) will include codes from INPO 19-003 Staying on Top and INPO 15-005 Leadership and Team Effectiveness Attributes.
How long does it take to score a year’s worth of data?
Times will vary depending on condition report volume, length, and computing hardware. However, a year’s worth of data can typically be scored in less than 8 hours for most sites.
What analytics do you provide out of the box?
Nuclearn includes an analytic engine specially designed for analyzing condition report data after it has been trendcoded. The built in analytics include the ability to calculate time trends, intra-company comparisons, and industry benchmark comparisons, and display these visually in a cluster visualization to quickly identify trends. Identified trends can quickly be saved as a “bucket”, and included in various reports.
I don’t agree with the predicted trendcodes sometimes. How can I trust the trends?
Applying codes is often very subjective, and even people usually disagree amongst themselves on what codes should be applied. Using Nuclearn’s model has a key advantage that people don’t have however: it is 100% consistent. This is absolutely critical for trending across many years of data, as inconsistent coding (especially over time) often results in spurious trends unrelated to underlying performance issues. While the model may be wrong on specific condition reports, applied over years of data these occasional inaccuracies are averaged out by the law of large numbers, allowing for effective trend analysis.
Can I connect PowerBI to Nuclearn?
While Nuclearn includes many built in analytics, you don’t have to solely rely upon them. Nuclearn supports PowerBI integrations at all points in the analytics pipeline – from initial datasets, to raw trendcode predictions and analytic results.
How are the predictions validated? Both internally and across industry?
We test our models internally using a variety of traditional machine learning
methods. These include calculating accuracy, F1 score, log-loss, and other
common metrics on test/validation data. Additionally, we look at other more
qualitative metrics such as “coverage” across rare codes. We also
subjectively evaluate outputs on a variety of CAP and non-CAP inputs to ensure
results make sense.
When we work with new customers we typically provide a set of predictions for a provided sample of their data, and they evaluate against that. We don’t always have direct insights into their audit/review processes, but they will usually perform tasks like:
- Evaluate predictions on a random sample of trend codes
- Perform a trend analysis (either using Nuclearn Cluster Visualization or their own tools), and validate that either a) the trends line up with trends they have identified using other techniques or b) upon further inspection the trends appear to be valid or explainable
- Compare predicted PO&Cs to previously applied internal trend codes (when available) to check if there are any major areas being missed
Why are the children trends captured and not just parents (e.g. why use specific trend codes instead of grouping up to the Objective level?
Grouping issues up at a very high level (e.g. at the objective level) is far too
broad and unlikely to identify important trends in our experience. For example, evaluation Areas for Improvement (AFIs) are usually created at an Objective level but they are almost always
representative of deficiencies in a sub-set of very specific things under that Objective. It’s very rare for a giant trend across most of the trend codes in a particular are.
It’s still important to group multiple low-level codes together, but usually in groups of 2-8. The “Cluster Visualizations” tools makes it easy to make “buckets” of codes easily.