Unlocking Efficiency and Innovation Through AI-Powered Process Engineering
The nuclear and utilities industries are experiencing an era of digital transformation, with AI agents at the heart of this evolution. These intelligent tools are revolutionizing traditional process engineering by automating repetitive tasks, analyzing complex datasets, and generating actionable insights. By embracing AI-driven solutions, organizations can optimize workflows, improve decision-making, and unlock new avenues for innovation.
This blog explores the profound impact of AI agents, the strategies for seamless integration, and the key benefits they bring to nuclear and utilities companies.
How AI Agents Are Reshaping Process Engineering
Process engineering in highly regulated industries like nuclear and utilities has long been a manual and resource-intensive effort. Engineers and operators spend countless hours analyzing workflows, identifying inefficiencies, and ensuring compliance with stringent regulations. AI agents take these capabilities to the next level, offering:
- Bottleneck Identification: AI can analyze historical data and operational trends to pinpoint inefficiencies within workflows.
- Predictive Maintenance: By monitoring equipment performance in real time, AI helps prevent failures and reduce unplanned downtime.
- Regulatory Compliance Automation: AI automates documentation reviews, ensuring compliance with industry standards and reducing administrative overhead.
- Data-Driven Insights: AI extracts and summarizes key findings from vast datasets, enabling faster, more informed decision-making.
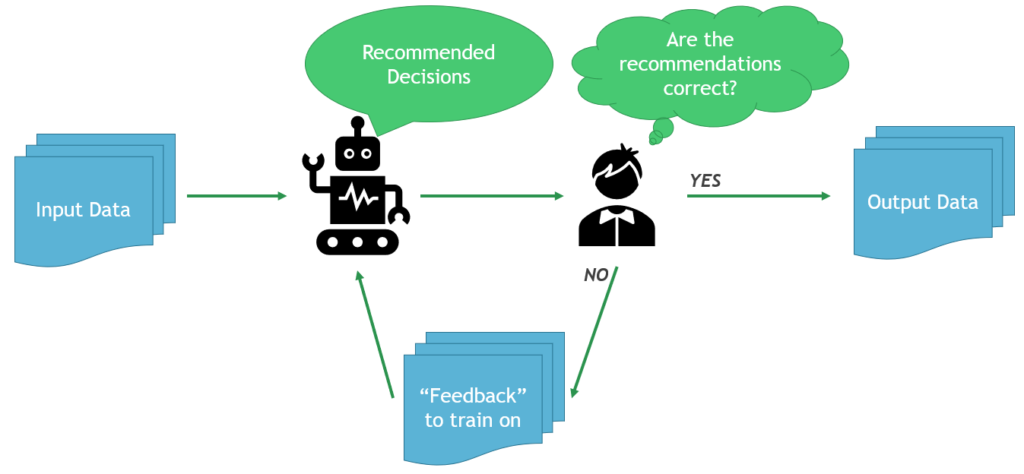
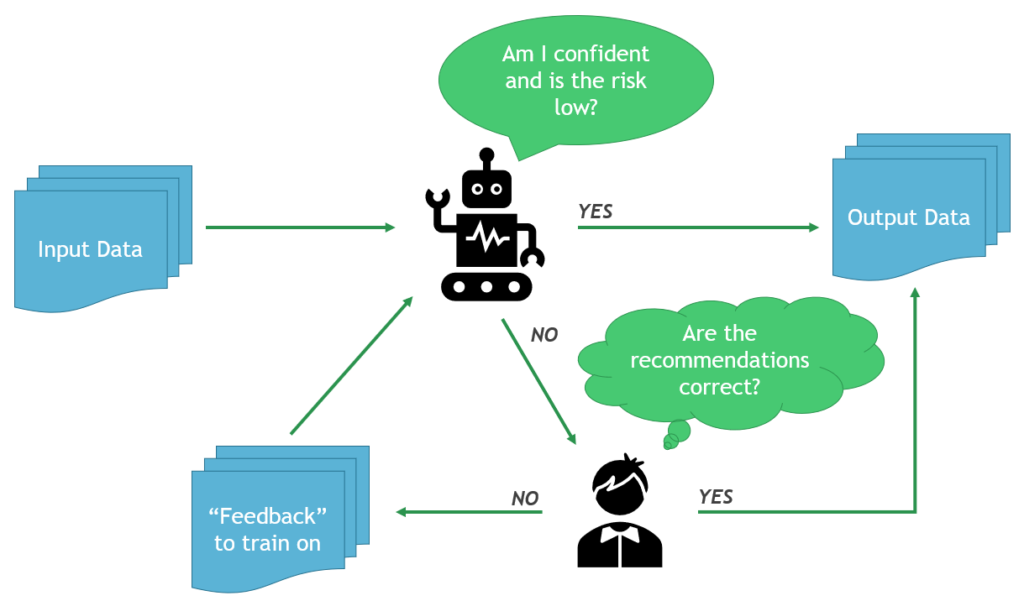
Rather than replacing human expertise, AI agents augment teams, allowing them to focus on strategic and high-value tasks. This shift not only enhances efficiency but also fosters a culture of continuous improvement within organizations.
Laying the Foundation for AI Integration
To successfully integrate AI agents into existing operations, organizations must align people, processes, and technology. A structured approach ensures seamless adoption and maximizes the value AI brings to business operations. Here are the essential strategies:
1. Cross-Departmental Collaboration
AI adoption should be a collaborative effort, involving engineers, IT teams, operations managers, and compliance experts. Establishing a cross-functional team ensures diverse perspectives and alignment with organizational goals.
2. Prioritizing High-Impact Use Cases
To build momentum, organizations should focus on AI applications with measurable impact. Key areas include:
- Automating regulatory document reviews
- Enhancing maintenance scheduling
- Streamlining incident reporting
- Real-time performance monitoring
3. Assigning AI Champions
To drive accountability and ensure success, appointing AI process owners within departments is crucial. These individuals oversee AI deployment, monitor performance, and advocate for continuous improvement.
4. Standardizing Workflows for AI Adoption
By creating uniform workflows, organizations make it easier for AI agents to integrate into operations. Standardized processes enable scalability and consistency across departments.
Achieving Early Wins to Drive AI Adoption
Demonstrating early success is vital for building confidence in AI technology. Quick-win initiatives can help showcase the immediate value AI delivers. Some effective early-stage applications include:
- Automating Regulatory Document Searches: AI reduces manual effort by quickly extracting and summarizing critical compliance information.
- Streamlining Maintenance Logs: AI assists in identifying and prioritizing critical maintenance tasks, reducing equipment downtime.
- Real-Time Reporting on Equipment Performance: AI-powered monitoring enables predictive maintenance, improving overall asset reliability.
By implementing these quick wins, organizations create a foundation for broader AI adoption and long-term digital transformation.
Tracking and Measuring AI’s Impact
To validate the success of AI initiatives, organizations must establish a framework for tracking efficiency gains. Key steps include:
- Setting Baseline Metrics: Measure time spent on manual processes before AI integration.
- Monitoring AI-Enabled Processes: Track improvements in efficiency and accuracy.
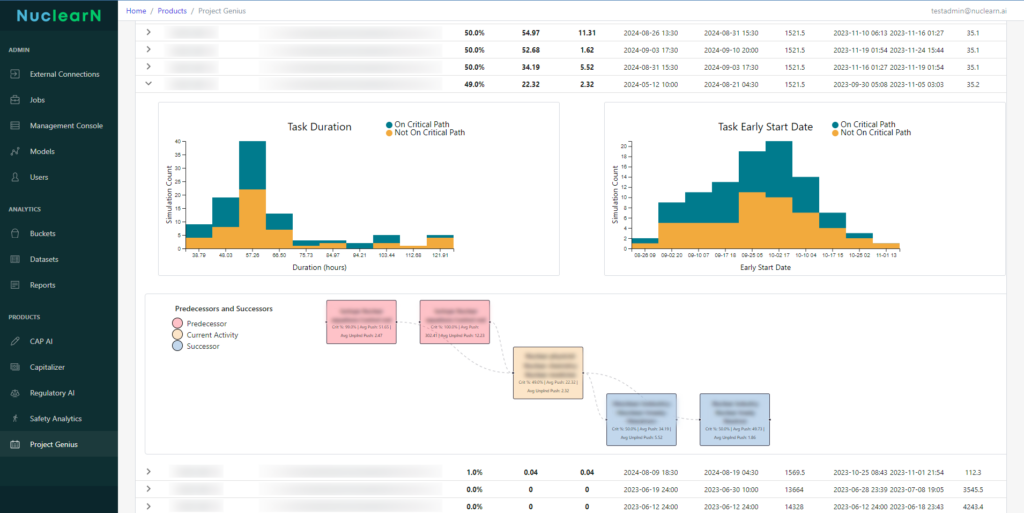
- Using Real-Time Dashboards: Visualize AI performance and workflow enhancements.
- Collecting User Feedback: Engage employees to gather insights on AI’s effectiveness and identify areas for further refinement.
By continuously assessing AI’s impact, organizations can optimize their strategies and ensure sustained improvements.
Bridging the AI Knowledge Gap
Despite AI’s potential, many organizations face challenges in adoption due to knowledge gaps and resistance to change. To overcome these hurdles, consider the following approaches:
- Collaborate with AI Experts: Partner with process re-engineering specialists to guide AI integration efforts.
- Develop Role-Specific Training Programs: Ensure employees understand how AI enhances their work.
- Leverage External Consultants: Work with AI implementation specialists to streamline deployment.
- Host Knowledge-Sharing Sessions: Encourage employees to discuss AI successes and challenges.
Bridging the knowledge gap empowers teams to embrace AI confidently and maximize its value.
A Vision for the Future: AI as a Strategic Partner
The digital transformation of the nuclear and utilities sectors is not about replacing human workers but enabling them to focus on more impactful tasks. Traditional methods of process engineering, while effective in their time, are now being revolutionized by AI’s ability to enhance precision, reduce human error, and adapt to evolving industry needs.
Organizations that proactively integrate AI into their workflows will:
- Increase operational efficiency
- Reduce compliance risks
- Improve asset reliability
- Foster innovation and adaptability
The key to success lies in starting small, demonstrating early value, and scaling AI initiatives with a structured governance framework.
The Time for Innovation is Now – Download the Research Brief
The nuclear and utilities industries are at a critical juncture where embracing AI is no longer optional—it is essential for staying competitive in a rapidly evolving landscape. By strategically integrating AI agents, organizations can drive operational excellence, ensure regulatory compliance, and unlock unprecedented efficiencies.
Ready to take the next step? Download our latest research brief today and discover how AI agents are transforming nuclear and utilities operations. Learn practical strategies for AI adoption, explore real-world use cases, and equip your organization with the knowledge to harness AI’s full potential.
Download the Research Brief Now
The future of AI-driven transformation begins with informed decision-making—secure your competitive advantage today.




 .
.