Sequoyah Nuclear Power Plant

In an era where digital fluency is the new literacy, Large Language Models (LLMs) have emerged as revolutionary game-changers. These models are not just regurgitating information; they’re learning procedures and grasping formal logic. This isn’t an incremental change; it’s a leap. They’re making themselves indispensable across sectors as diverse as finance, healthcare, and cybersecurity. And now, they’re lighting up a path forward in another high-stakes arena: the nuclear sector.
The Limits of One-Size-Fits-All: Why Specialized Domains Need More Than Standard LLMs
In today’s digital age, Large Language Models (LLMs) like GPT-4 have become as common as smartphones, serving as general-purpose tools across various sectors. While their wide-ranging training data, which spans from social media to scientific papers, is useful for general capabilities, this limits their effectiveness in specialized domains. This limitation is especially glaring in fields that require precise and deep knowledge, such as nuclear physics or complex legal systems. It’s akin to using a Swiss Army knife when what you really need is a surgeon’s scalpel.
In contrast, specialized fields like nuclear engineering demand custom-tailored AI solutions. Publicly-available LLMs lack the precision needed to handle the nuanced language, complex protocols, and critical safety standards inherent in these areas. Custom-built AI tools go beyond mere language comprehension; they become repositories of essential field-specific knowledge, imbued with the necessary legal norms, safety protocols, and operational parameters. By focusing on specialized AI, we pave the way for more reliable and precise tools, moving beyond the “Swiss Army knife” approach to meet the unique demands of specialized sectors.
LLMs are Swiss Army knives in that they are great at a multitude of tasks; this is paradoxical to their utility in a field like nuclear where nuance is everything.
The Swiss Army Knife In Action
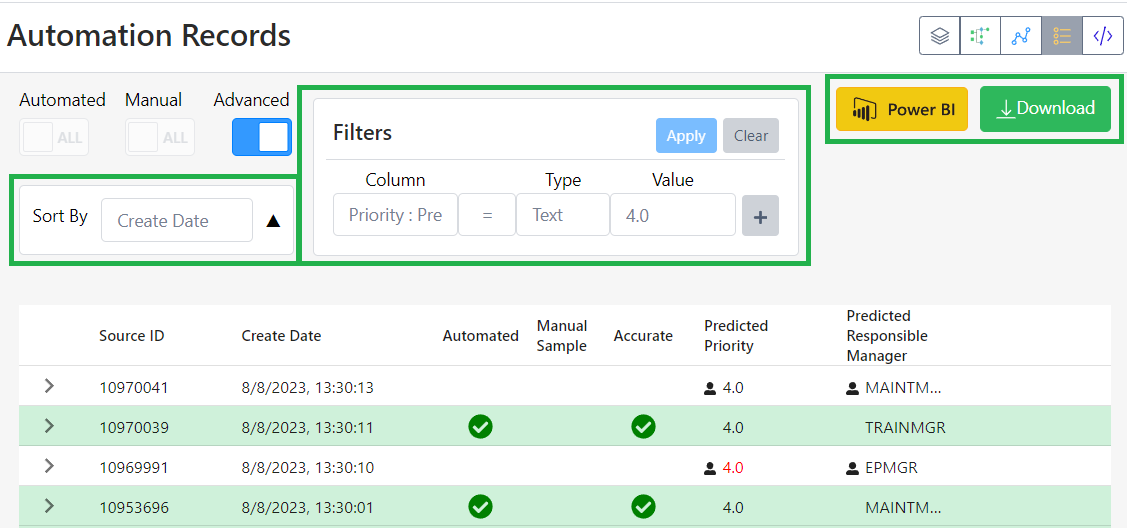
Below is a common response from a public chatbot on most plant specific questions. The information about this site is widely available online and has been published well before 2022 with the power plant’s commission date occurring in 1986.
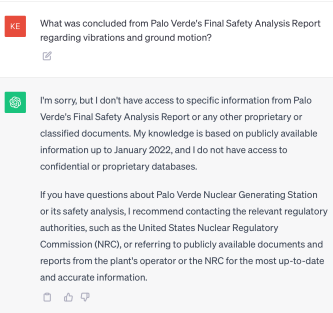
From the chatbot’s response, the generic information provided by this public-available model does not give enough clarity for experts to rely on. To answer the above question, the model will need to be adapted to a specific domain.
Adapting general models to be domain specific is not easy however. Some challenges with this task include:
- Financial and Technical Hurdles in Fine-Tuning—Fine-tuning public models is a costly affair. Beyond the financial aspect, modifications risk destabilizing the intricate instruct/RLHF tuning, a nuanced balance established by experts.
- Data Security: A Custodian Crisis —Public models weren’t built with high-security data custodianship in mind. This lack of a secure foundation poses risks, especially for sensitive information.
- A Dead End for Customization—Users face a brick wall when it comes to customizing these off-the-shelf models. Essential access to model weights is restricted, stifling adaptability and innovation.
- Stagnation in Technological Advancement —These models lag behind, missing out on revolutionary AI developments like RLAIF, DPO, or soft prompting. This stagnation limits their applicability and efficiency in evolving landscapes.
- The Impossibility of Refinement and Adaptation—Processes integral for optimization, such as model pruning, knowledge distillation, or weight sharing, are off the table. Without these, the models remain cumbersome and incompatible with consumer-grade hardware.
NuclearN
NuclearN specializes in AI-driven solutions tailored for the nuclear industry, combining advanced hardware, expert teams, and a rich data repository of nuclear information to create Large Language Models (LLMs) that excel in both complexity and precision. Unlike generic LLMs, ours are fine-tuned with nuclear-specific data, allowing us to automate a range of tasks from information retrieval to analytics with unparalleled accuracy.
What makes our models better than off-the-shelf LLMs?
Large Language Models (LLMs) from NuclearN are trained on specialized nuclear data that are transforming several core tasks within the nuclear industry, leveraging their vast knowledge base and advanced understanding of nuclear context-specific processes. These models, when expertly trained with the right blend of data, algorithms, and parameters, can facilitate a range of complex tasks and information management functions with remarkable efficiency and precision.
NuclearN is training our LLMs to enhance several core functions:
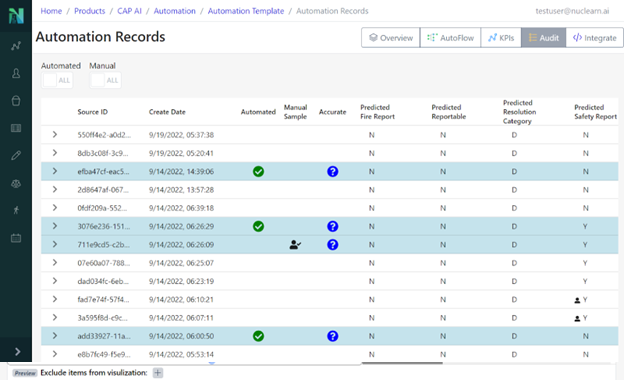
- Routine Question-Answering: NuclearN’s trains LLMs on a rich dataset of nuclear terminologies, protocols, and safety procedures. They offer accurate and context-aware answers to technical and procedural questions, serving as a reliable resource that reduces the time needed for research and minimizes human error.
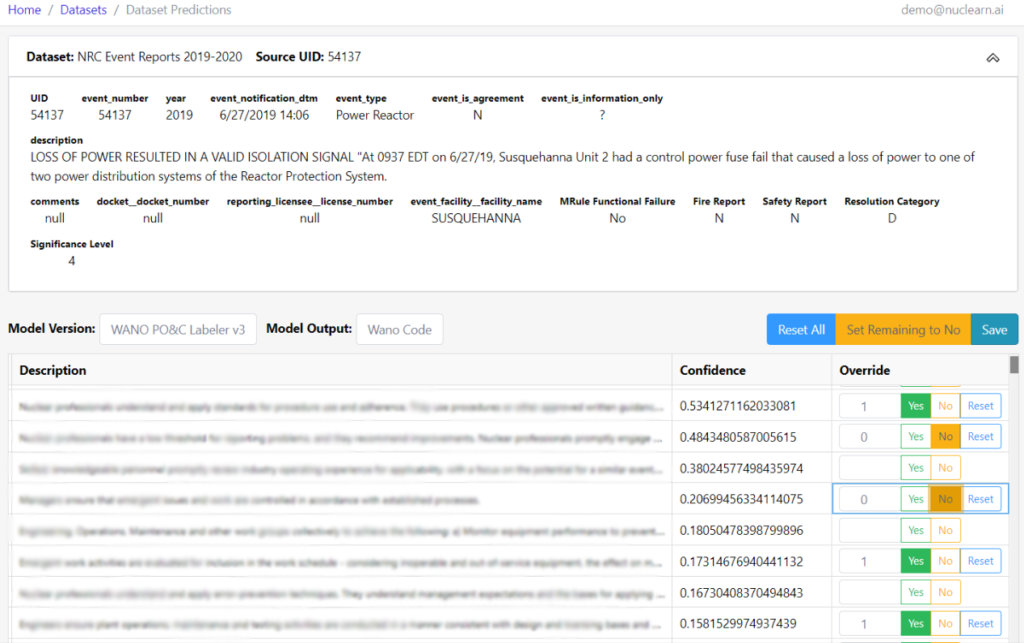
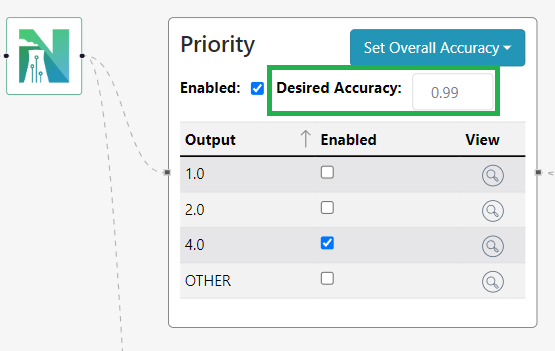
- Task-Specific and Site-Specific Fine Tuning: Even though our LLMs are trained to be nuclear-specific, different sites can have very specific plant designs, processes, and terminology. Tasks such as engineering evaluations or work instruction authoring may be performed in a style unique to the site. NuclearN offers private and secure, site and task-specific fine tuning of our LLMs to meet these needs and deliver unparalleled performance.
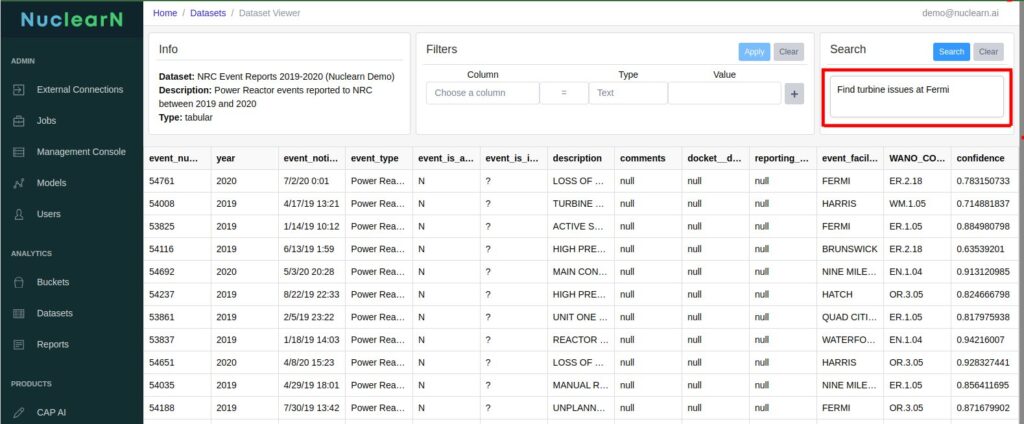
- Neural Search: The search capabilities of our LLMs go beyond mere keyword matching. They understand the semantic and contextual relationships between different terminologies and concepts in nuclear science. This advanced capability is critical when one needs to sift through large volumes of varied documents—be it scientific papers, historical logs, or regulatory guidelines—to extract the most pertinent information. It enhances both the efficiency and depth of tasks like literature review and risk assessment.
- Document Summarization: In an industry awash with voluminous reports and papers, the ability to quickly assimilate information is vital. Our LLMs can parse through these lengthy documents and distill them into concise yet comprehensive summaries. They preserve key findings, conclusions, and insights, making it easier for professionals to stay informed without being overwhelmed by data.
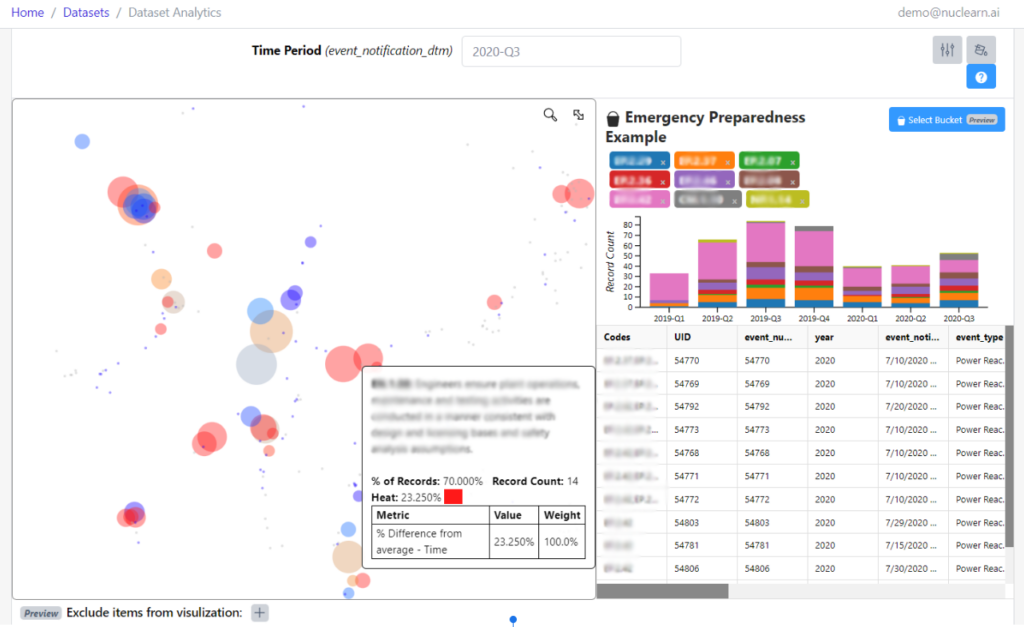
- Trend Analysis from Time-Series Data: The nuclear industry often relies on process and operational data gathered from sensors in the plant to track equipment performance and impacts from various activities. NuclearN is training our LLMs to be capable of analyzing these time-series data sets to discern patterns, correlations, or trends over time. This allows our LLMs to have a significantly more comprehensive view of the plant, which is particularly valuable for monitoring equipment health and predicting operational impacts.
By leveraging the capabilities of NuclearN’s specialized LLMs in these functional areas, the nuclear industry can realize measurable improvements in operational efficiency and strategic decision-making.
Stay informed and engaged with everything AI in the nuclear sector by visiting The NuclearN Blog. Join the conversation and be part of the journey as we explore the future of AI in nuclear technology together.
 .
.